Example data in the package
df <- pmplots_data_obs() %>% mutate(CWRES = CWRESI)
id <- pmplots_data_id()
dayx <- defx(breaks = seq(0,168,24))
.yname <- "MRG1557 (ng/mL)"
etas <- c("ETA1//ETA-CL", "ETA2//ETA-V2", "ETA3//ETA-KA")
covs <- c("WT//Weight (kg)", "ALB//Albumin (g/dL)", "SCR//Creatinine (mg/dL)")Override the df and id objects in the above
chunk
## Nothing here
col//title specification
This is a way to specify the column name for source data along with the axis label
col_label("CL//Clearance (L)"). [1] "CL" "Clearance (L)"When only the column is given, then the column name will be used for the column title:
col_label("WT"). [1] "WT" "WT"Generate using the yspec package
You can also pull col//title data from a
yspec object. Load the yspec package and
generate an example data specification object
Typically, you’ll want to select a subset of columns and then call
axis_col_labs()
spec %>%
ys_select(WT, AGE, BMI) %>%
axis_col_labs(). WT AGE BMI
. "WT//weight (kg)" "AGE//age (years)" "BMI//BMI (m2/kg)"You should install the yspec to use this
functionality.
Fill in CWRES if it doesn’t exist
dat <- mutate(df, CWRES = NULL)
cwresi_time(df).
[1m
[22m`geom_smooth()` using formula = 'y ~ x'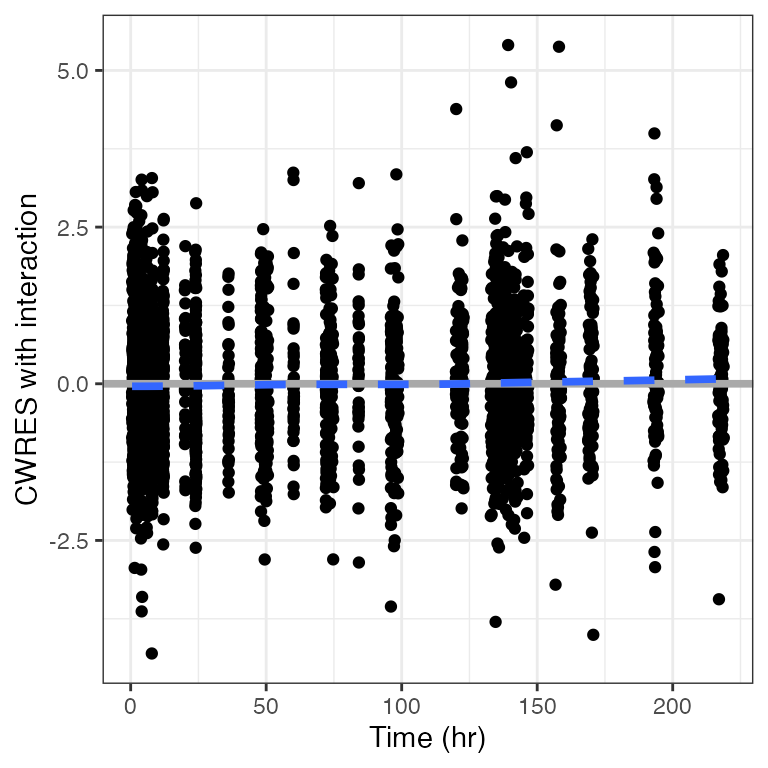
cwres_time(dat). Creating CWRES column from CWRESI
.
[1m
[22m`geom_smooth()` using formula = 'y ~ x'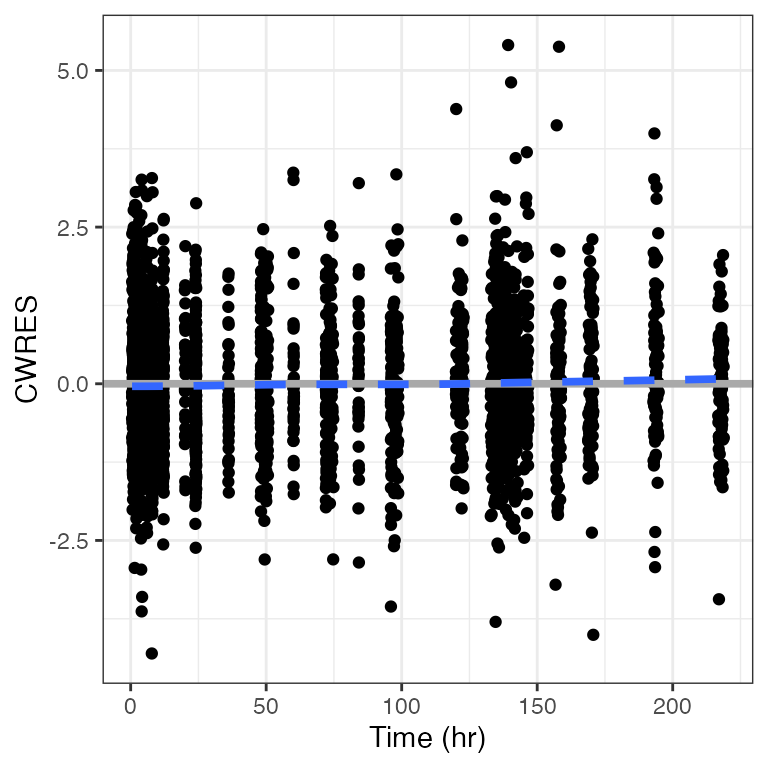
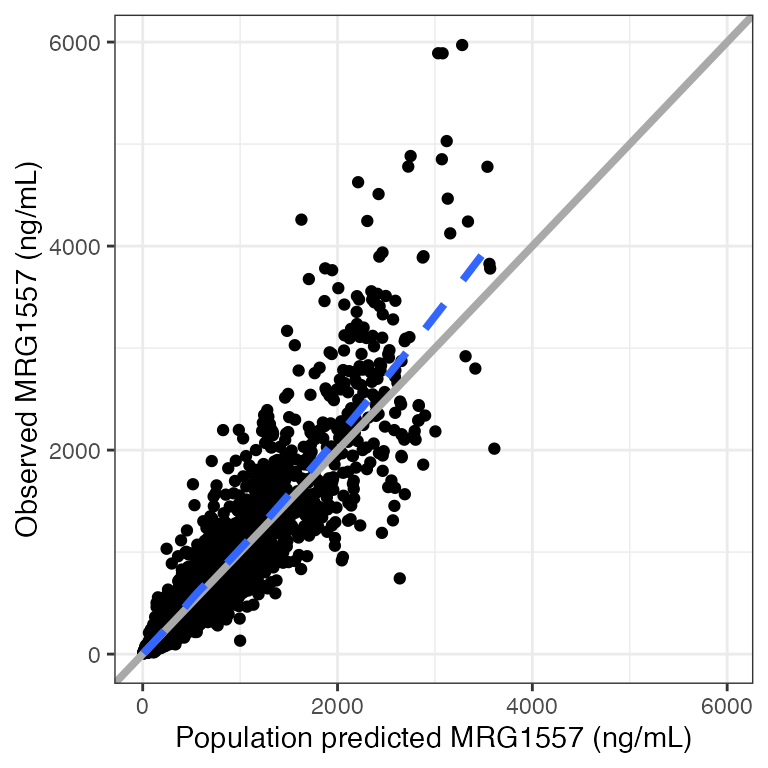
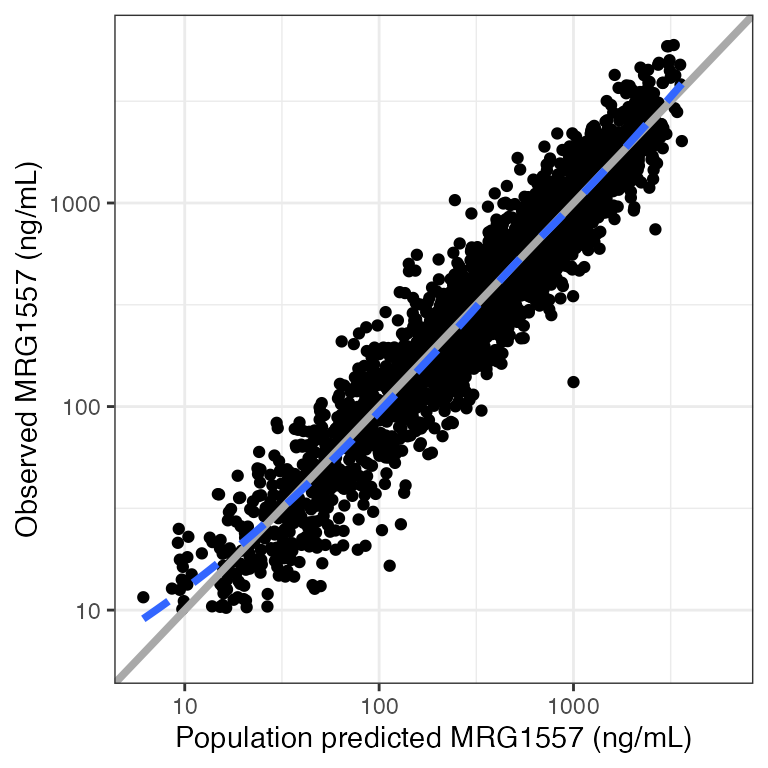
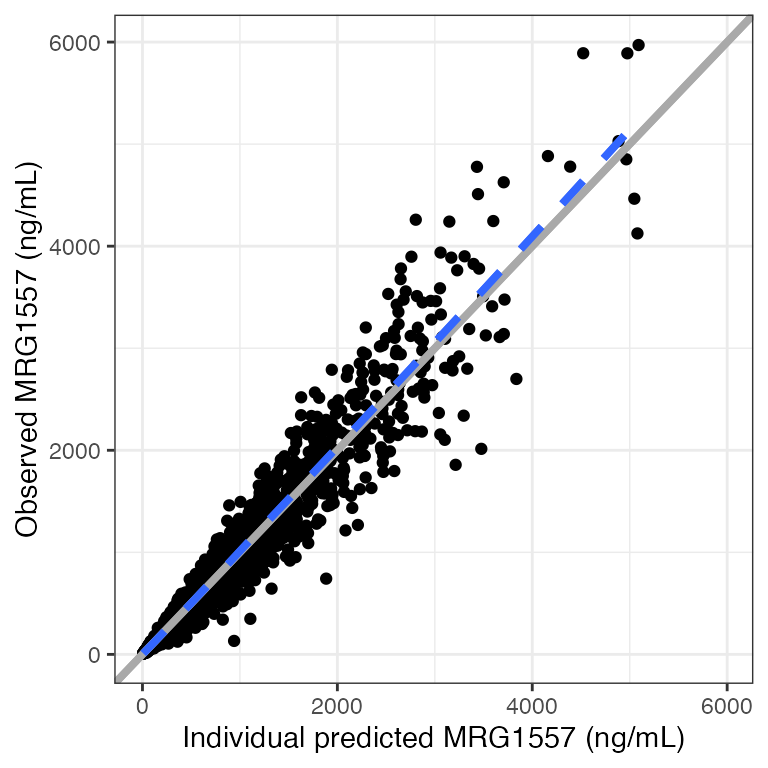
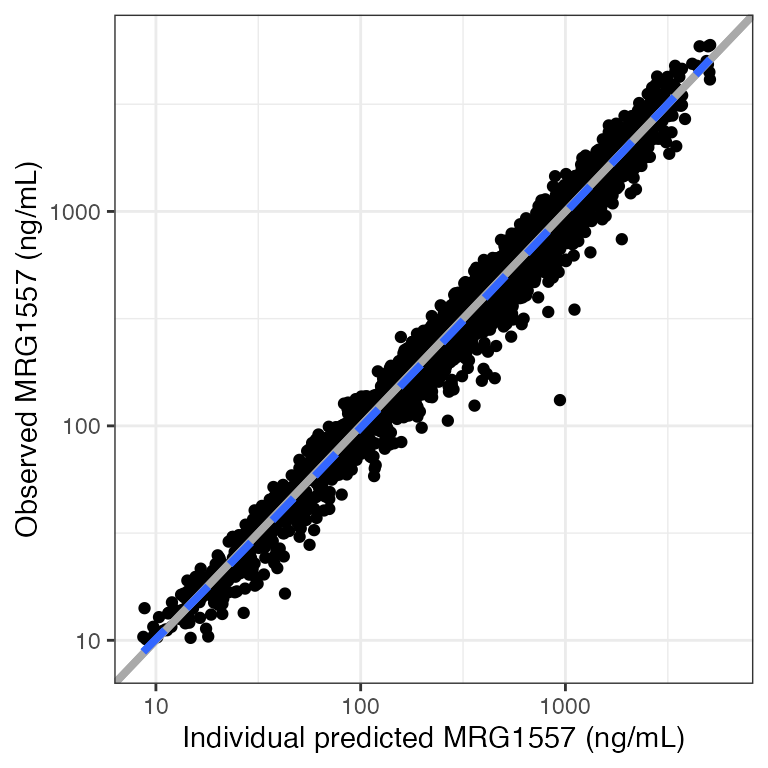
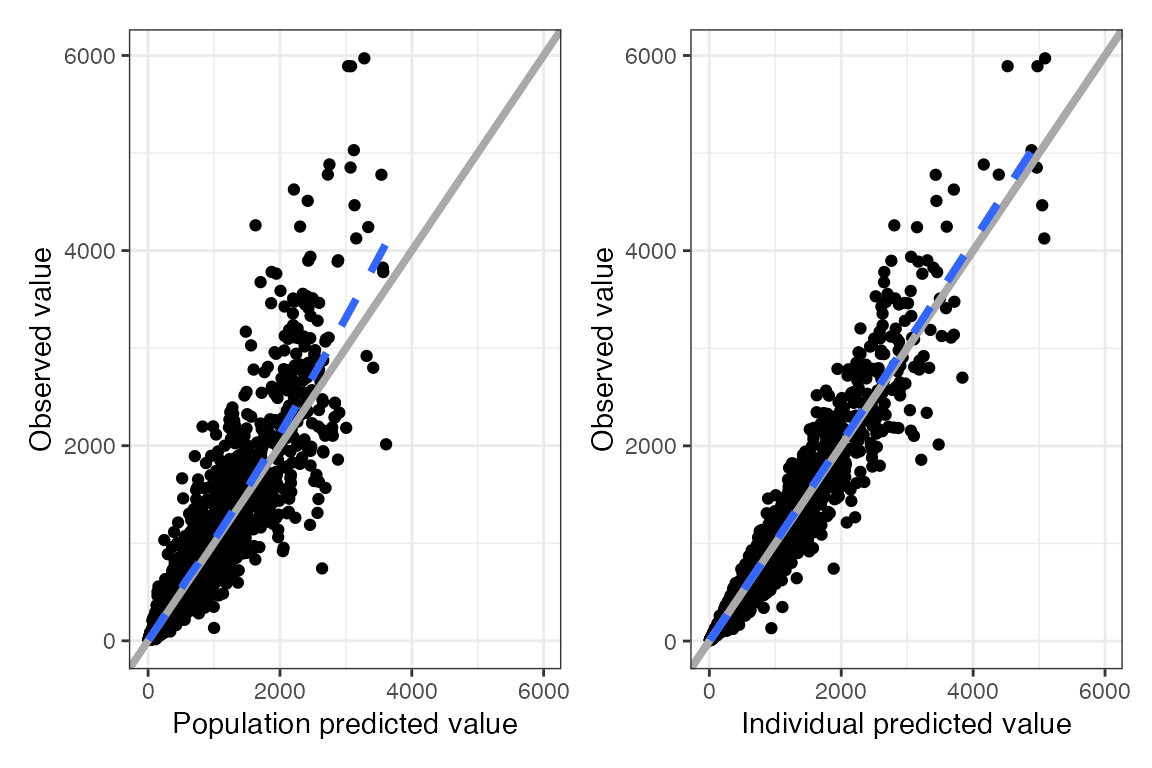
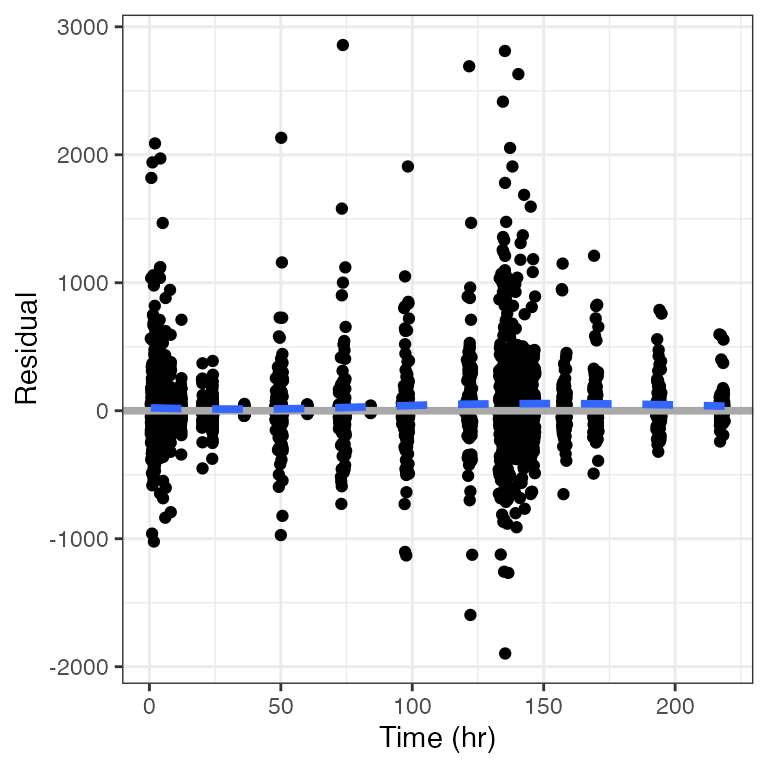
Residual plots
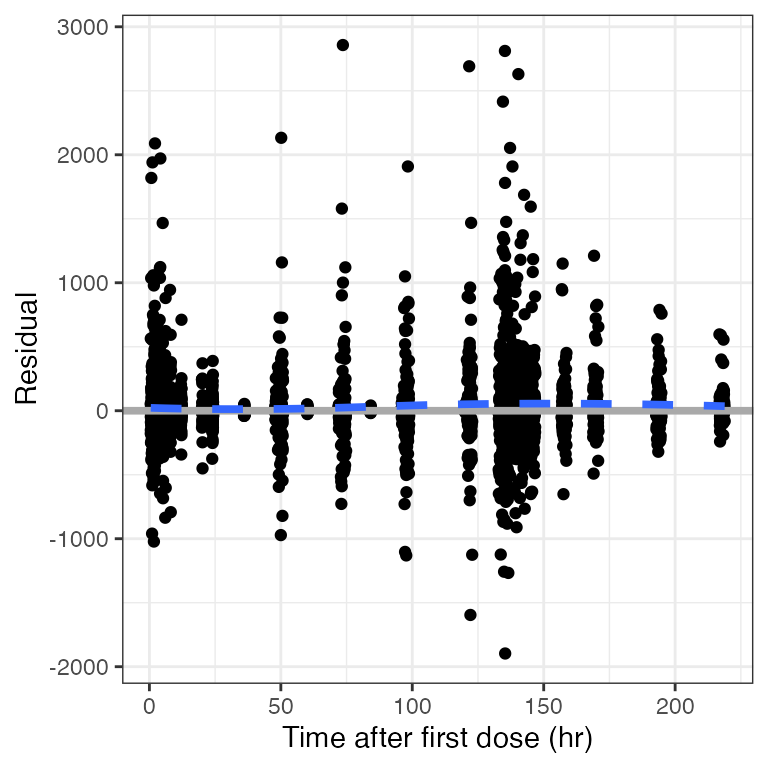
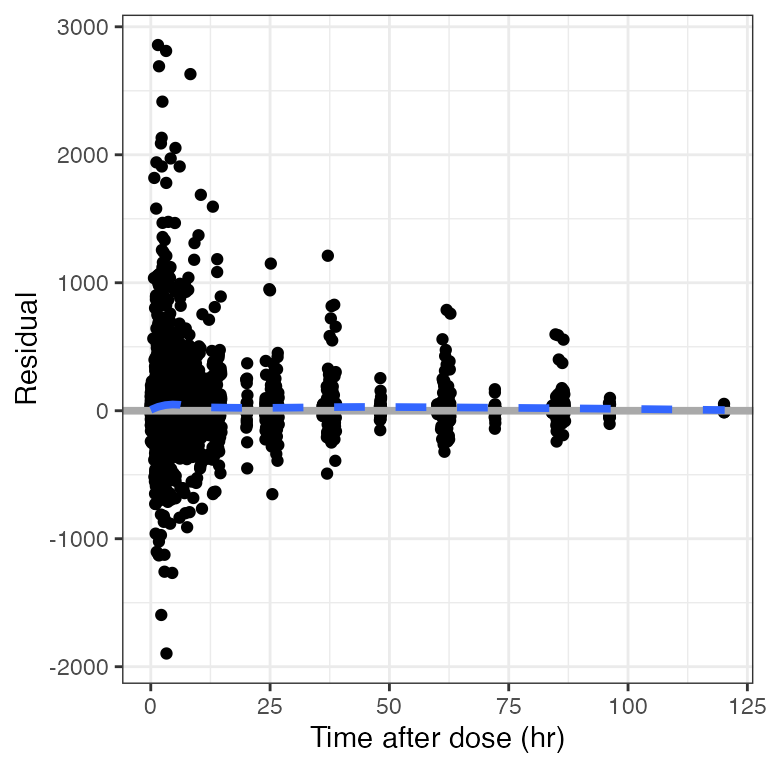
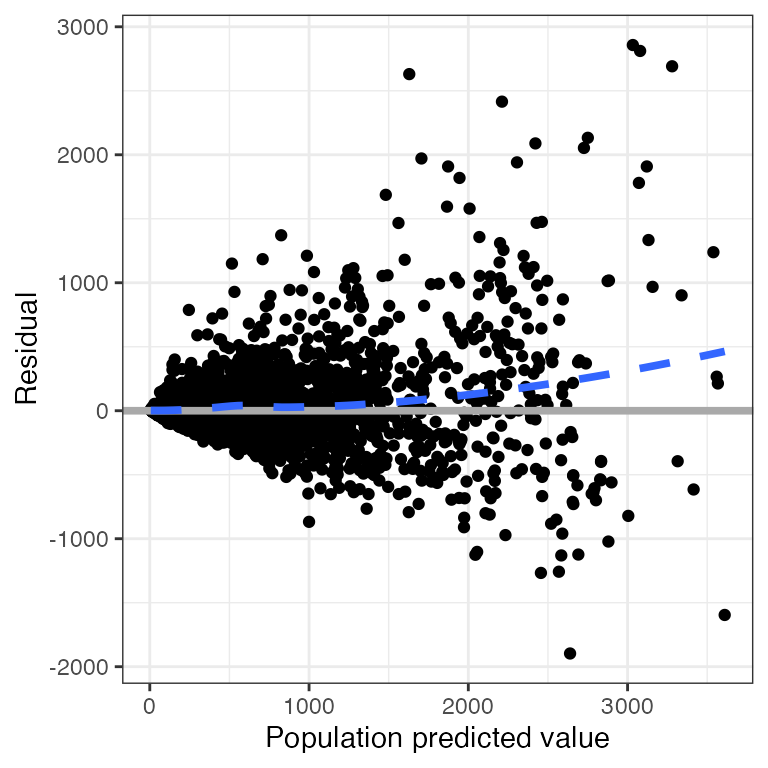
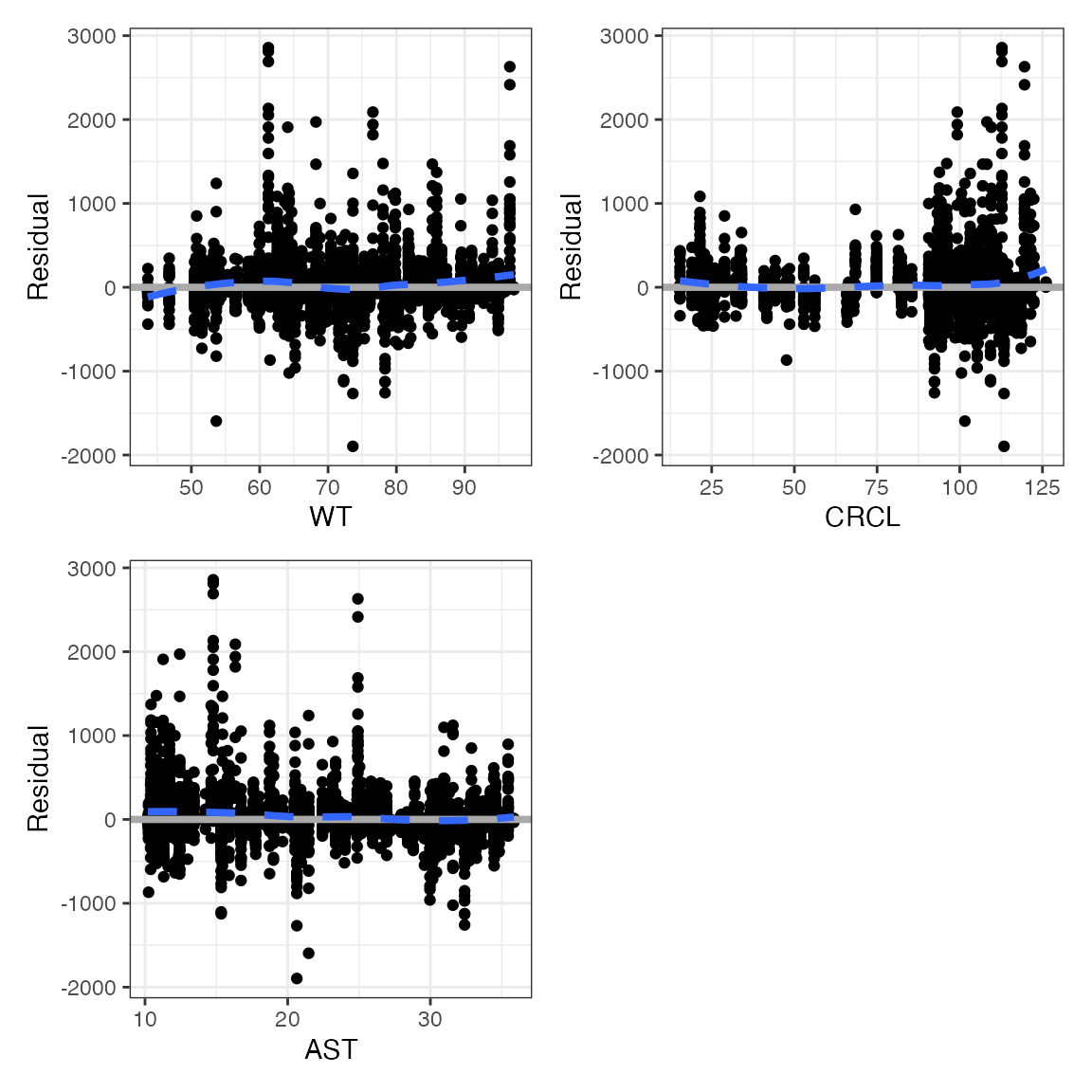
RES versus continuous covariate (res_cont)
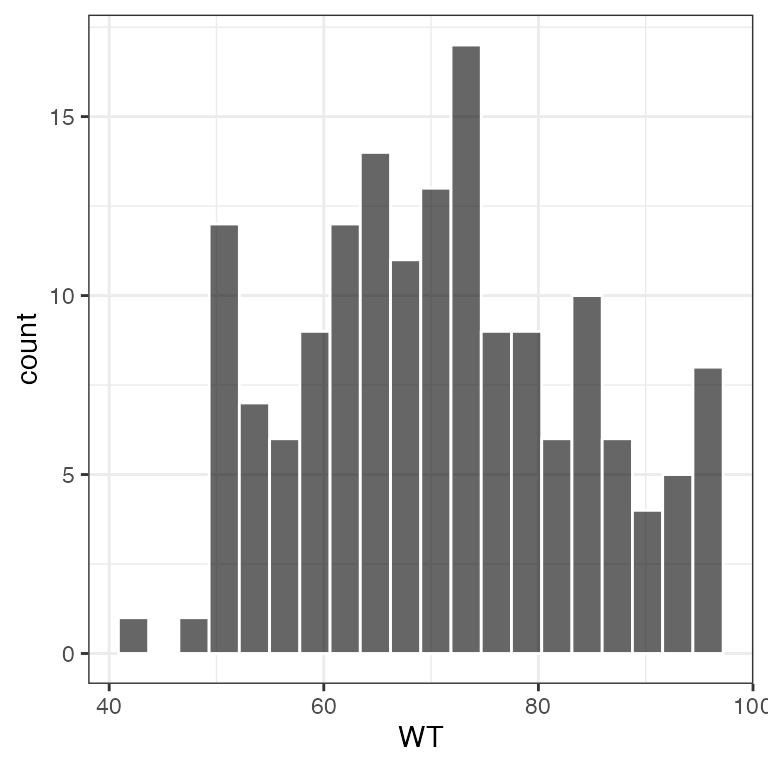
res_cont(df, x="WT//Weight (kg)")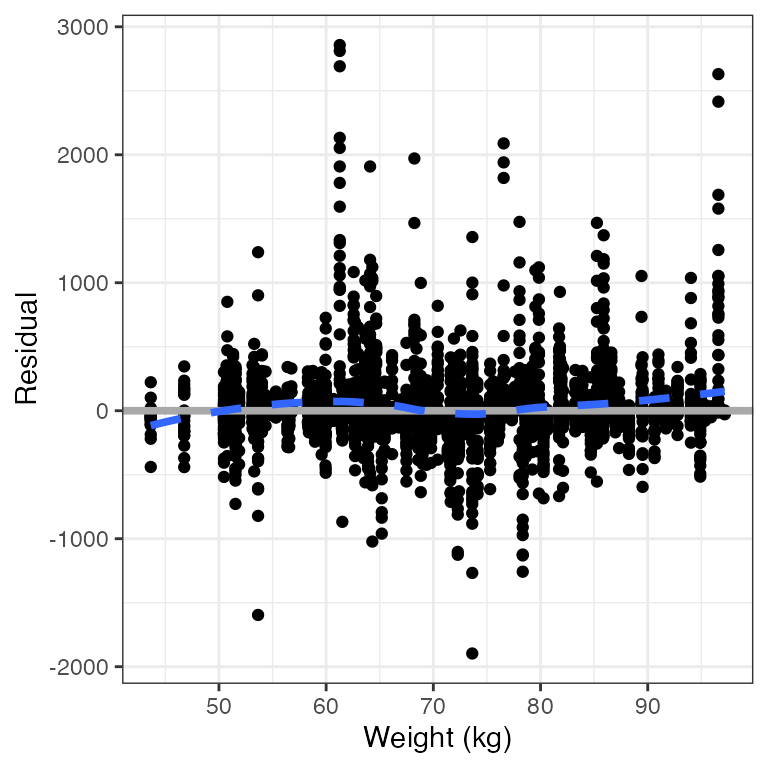
This function is also vectorized in x.
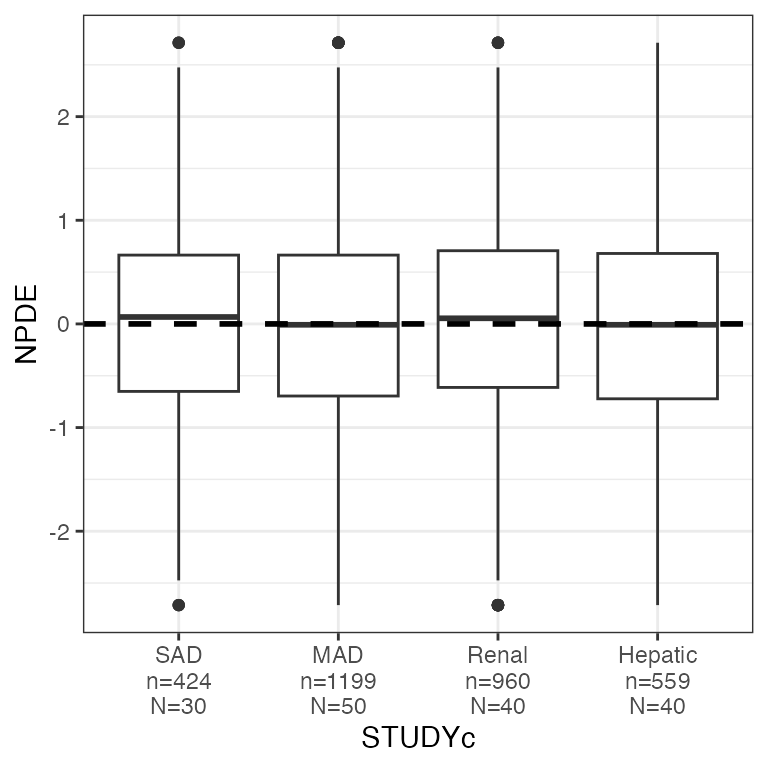
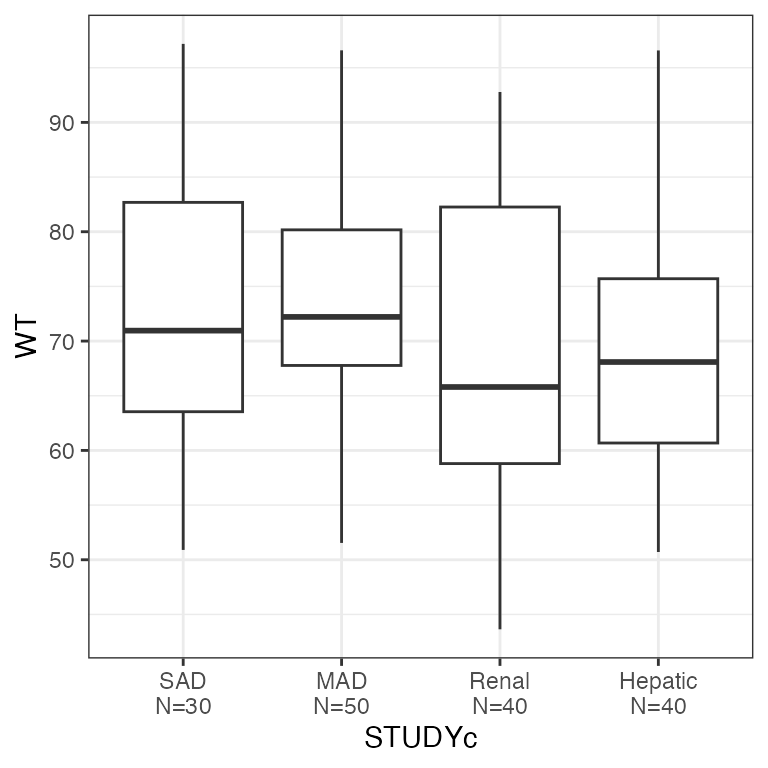
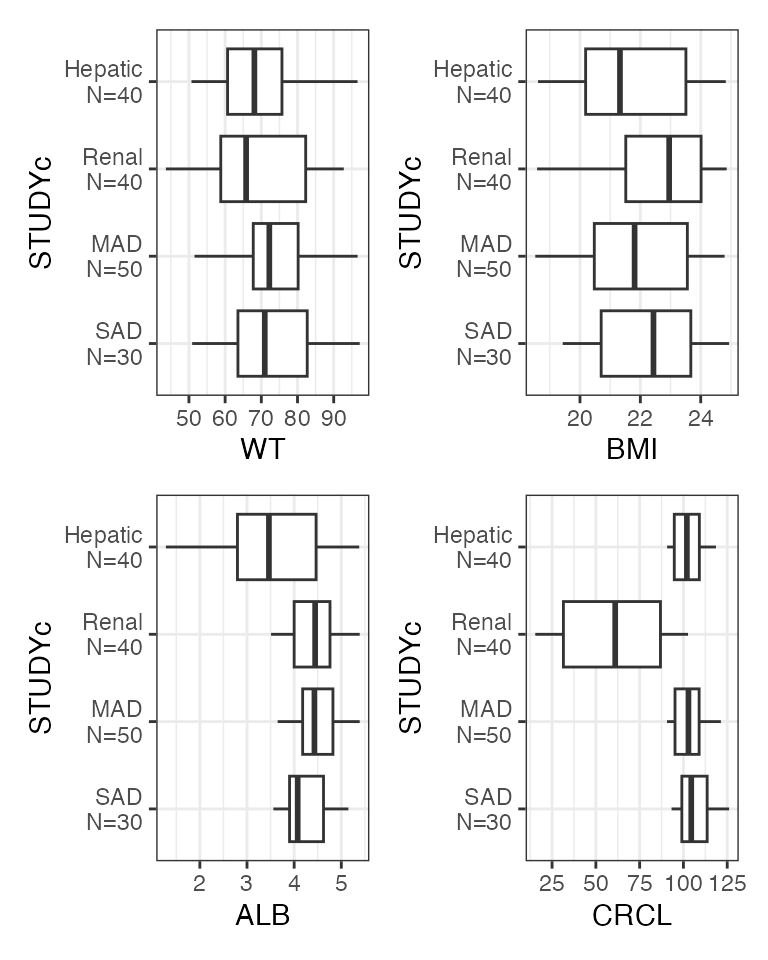
RES by categorical covariate (res_cat)
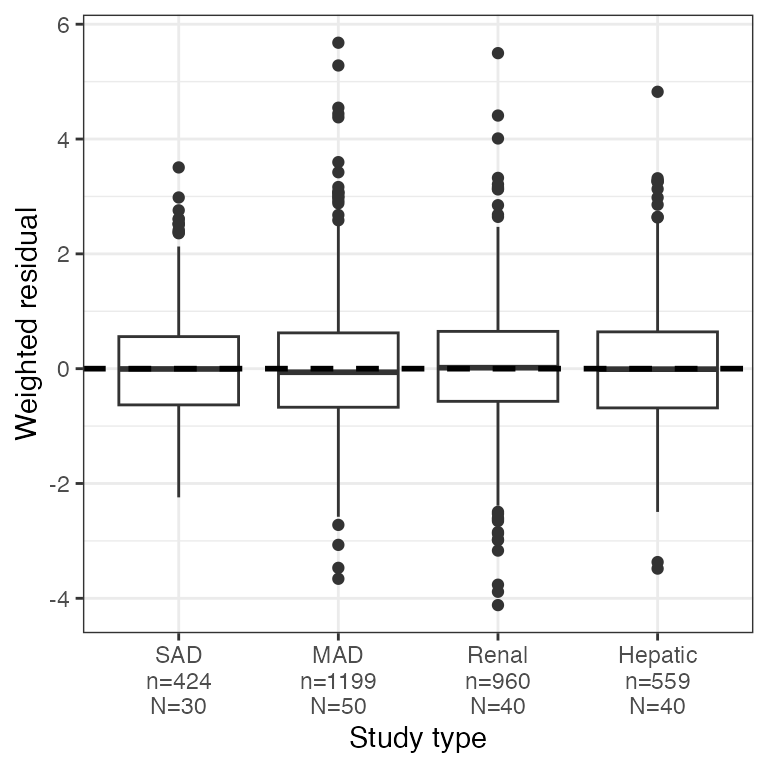
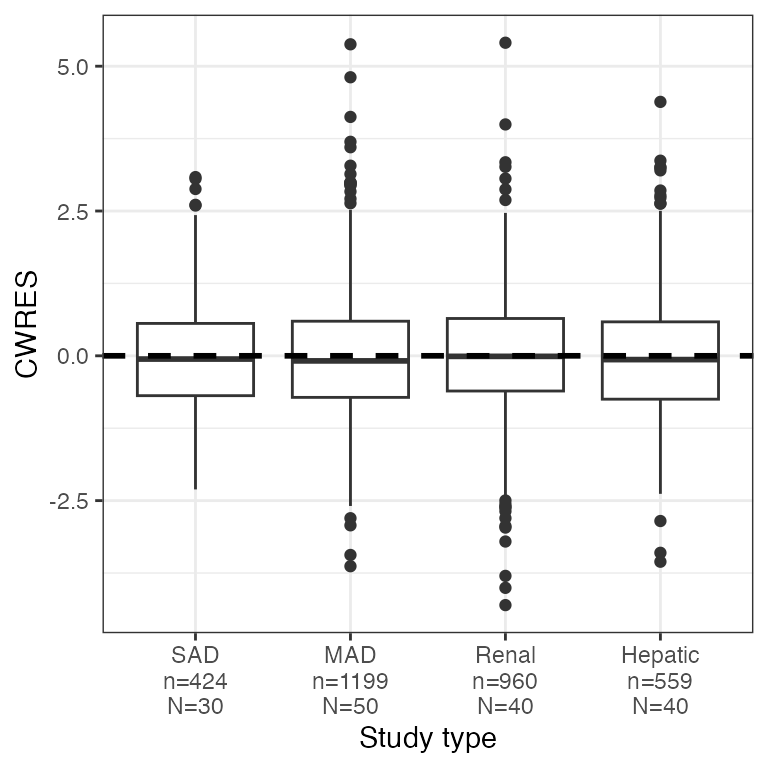
dplyr::count(df, STUDYc).
[38;5;246m# A tibble: 4 × 2
[39m
. STUDYc n
.
[3m
[38;5;246m<fct>
[39m
[23m
[3m
[38;5;246m<int>
[39m
[23m
.
[38;5;250m1
[39m SAD 424
.
[38;5;250m2
[39m MAD
[4m1
[24m199
.
[38;5;250m3
[39m Renal 960
.
[38;5;250m4
[39m Hepatic 559
res_cat(df, x="STUDYc//Study type")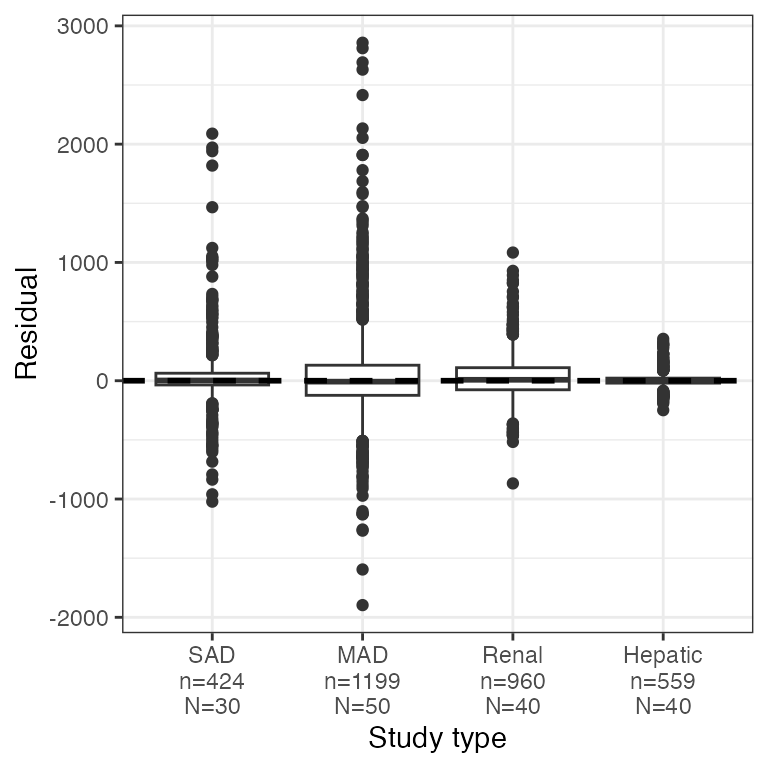
Weighted residuals
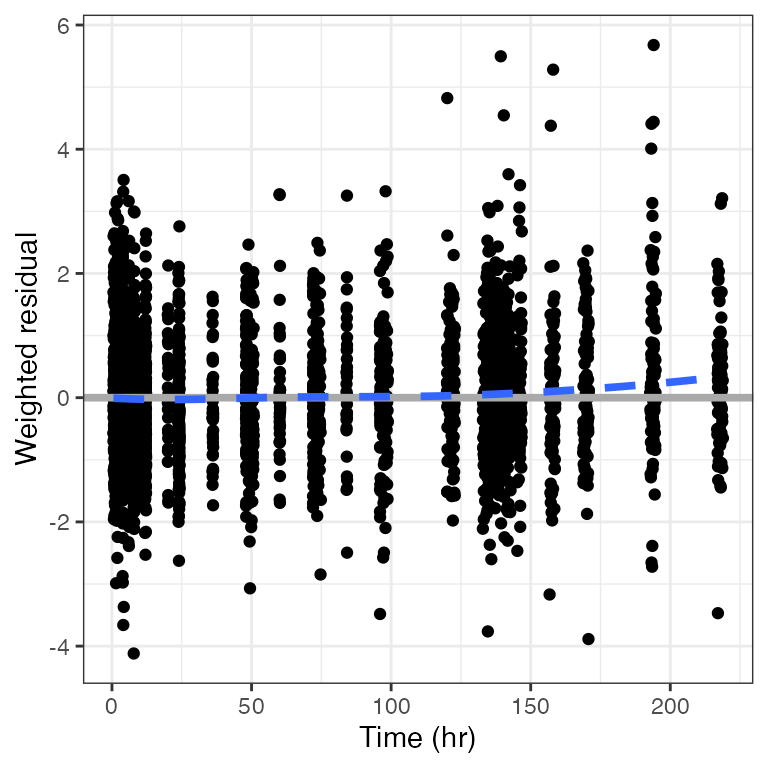
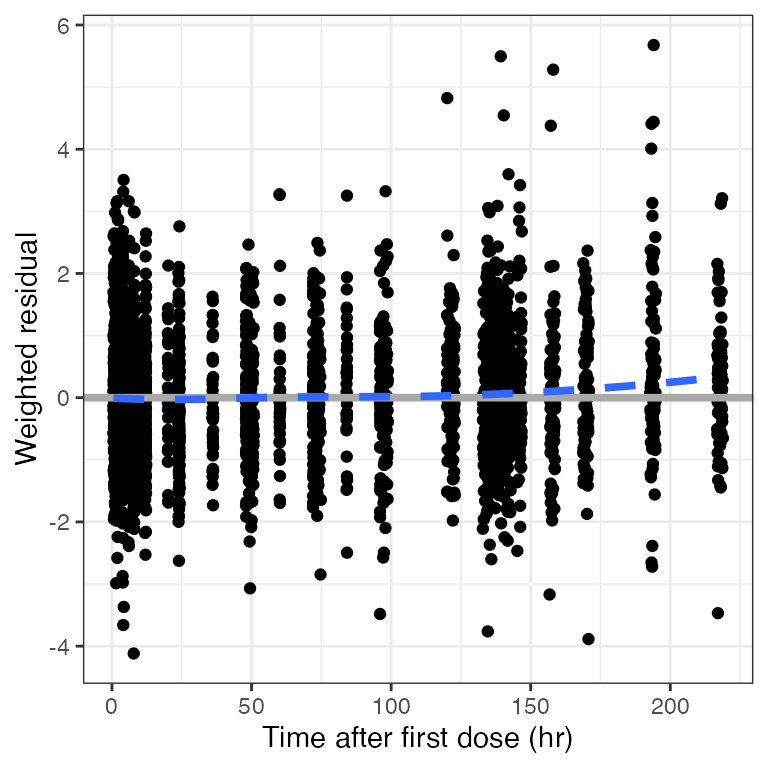
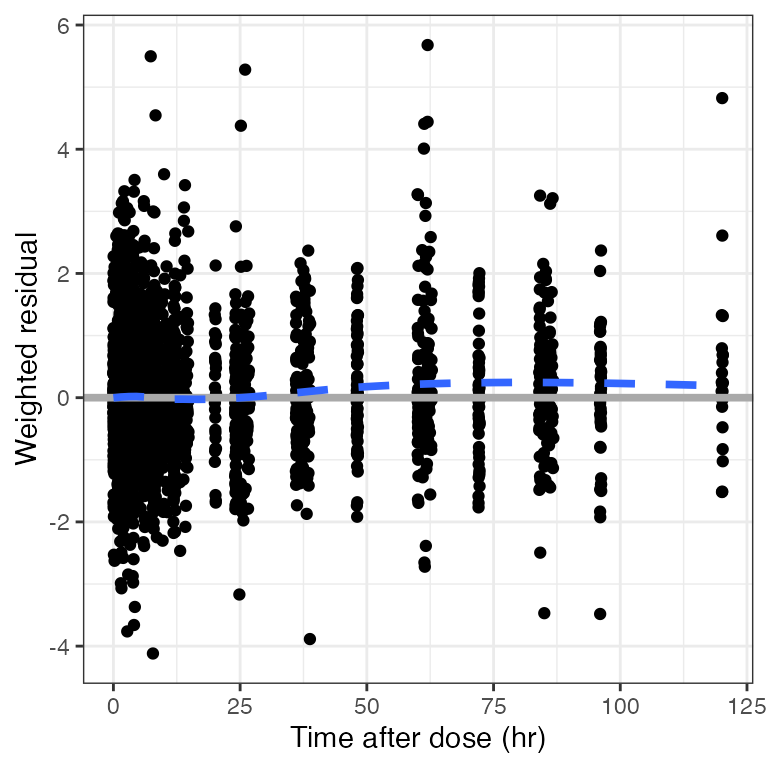
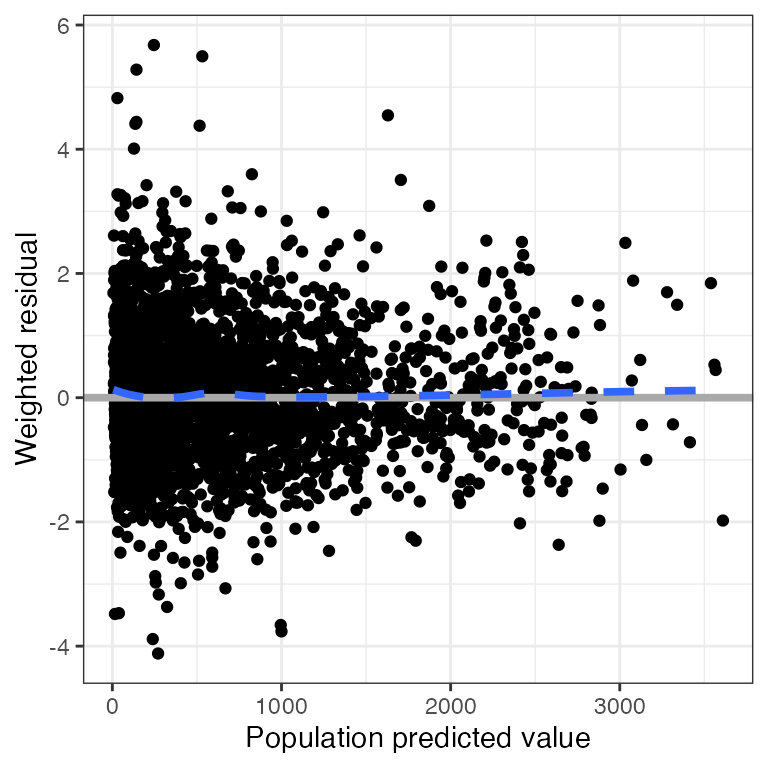
WRES versus continuous covariate (wres_cont)
This function is also vectorized in x.
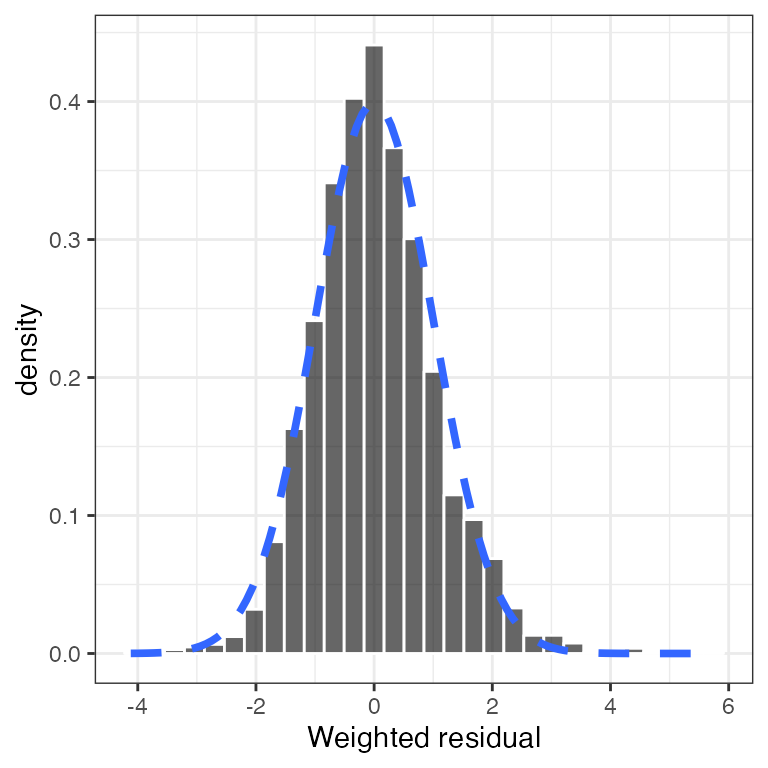
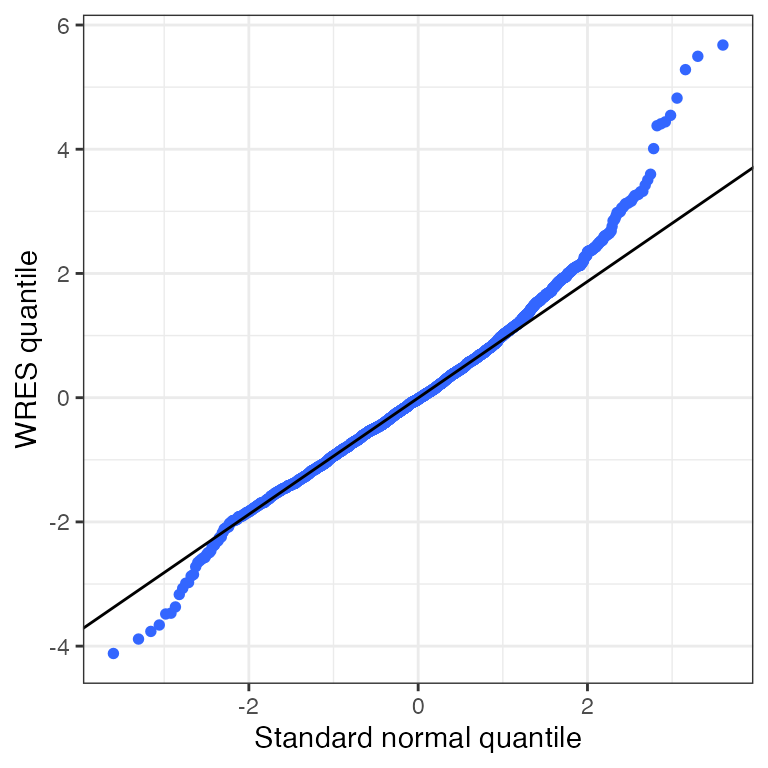
wres_cont(df, x="WT//Weight (kg)")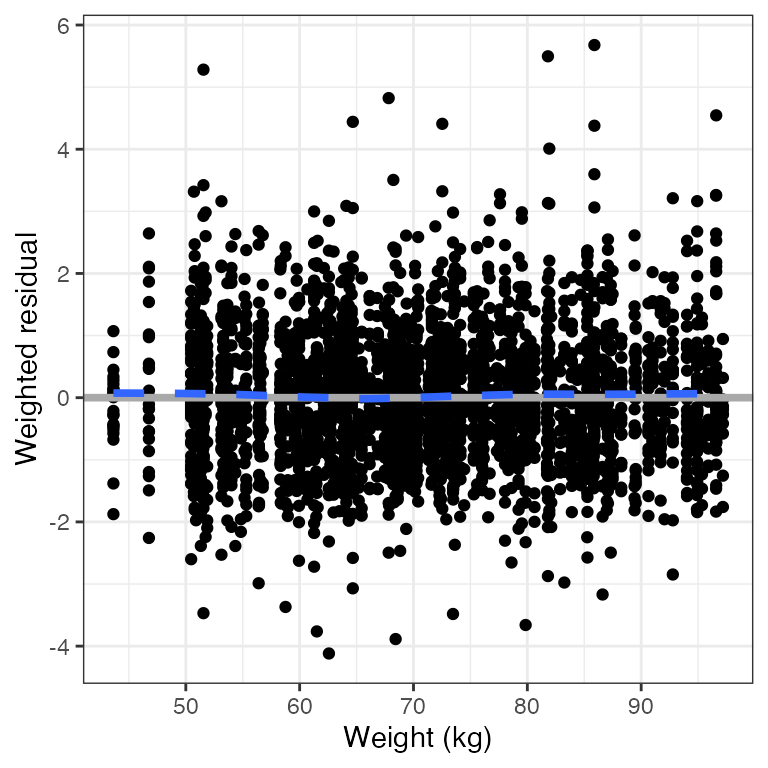
Conditional weighted residuals (CWRES)
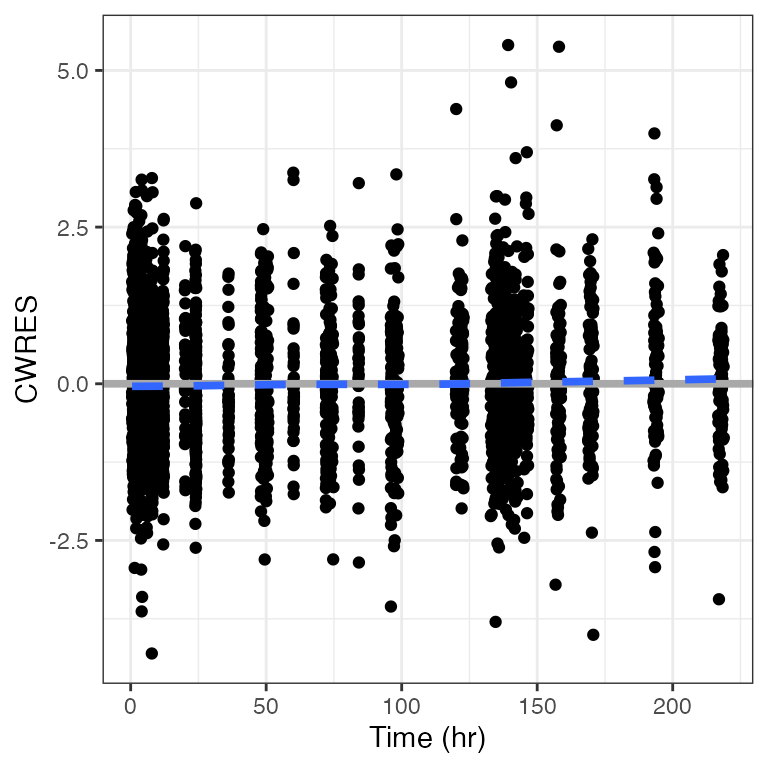
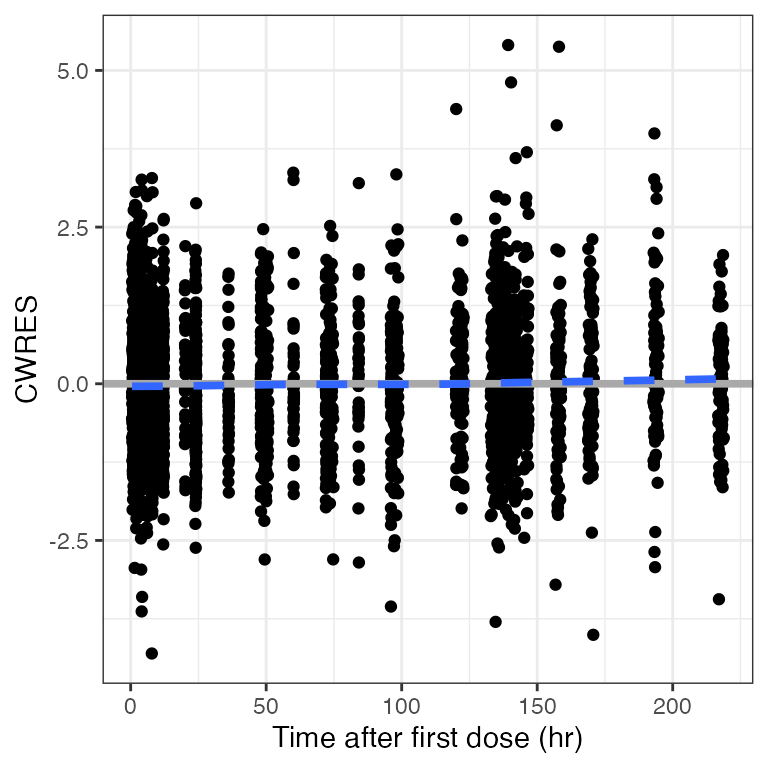
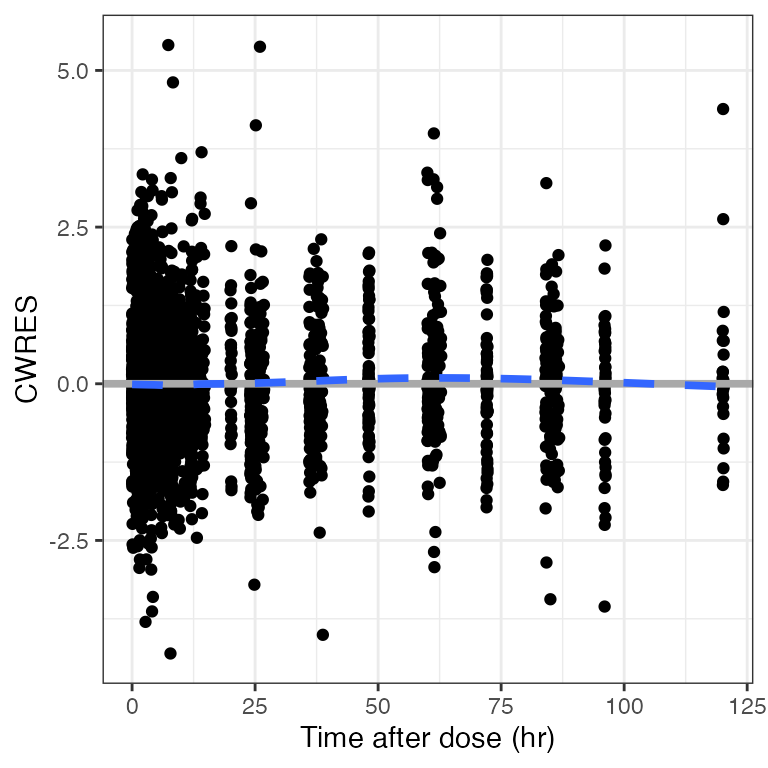
CWRES versus continuous covariate (cwres_cont)
cwres_cont(df, x="WT//Weight (kg)")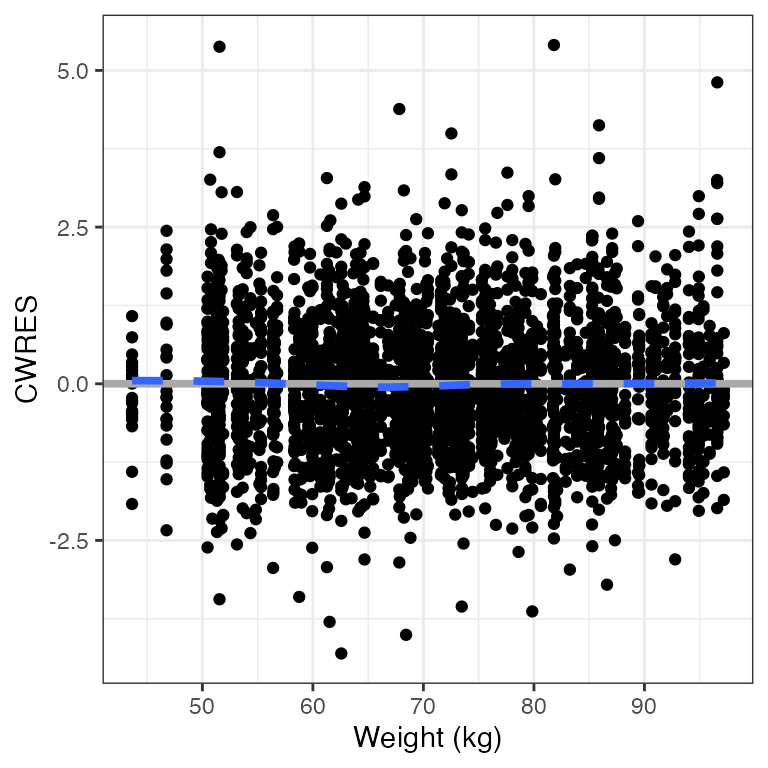
Vectorized version
cwres_cont(df, covs) %>% pm_grid(ncol=2)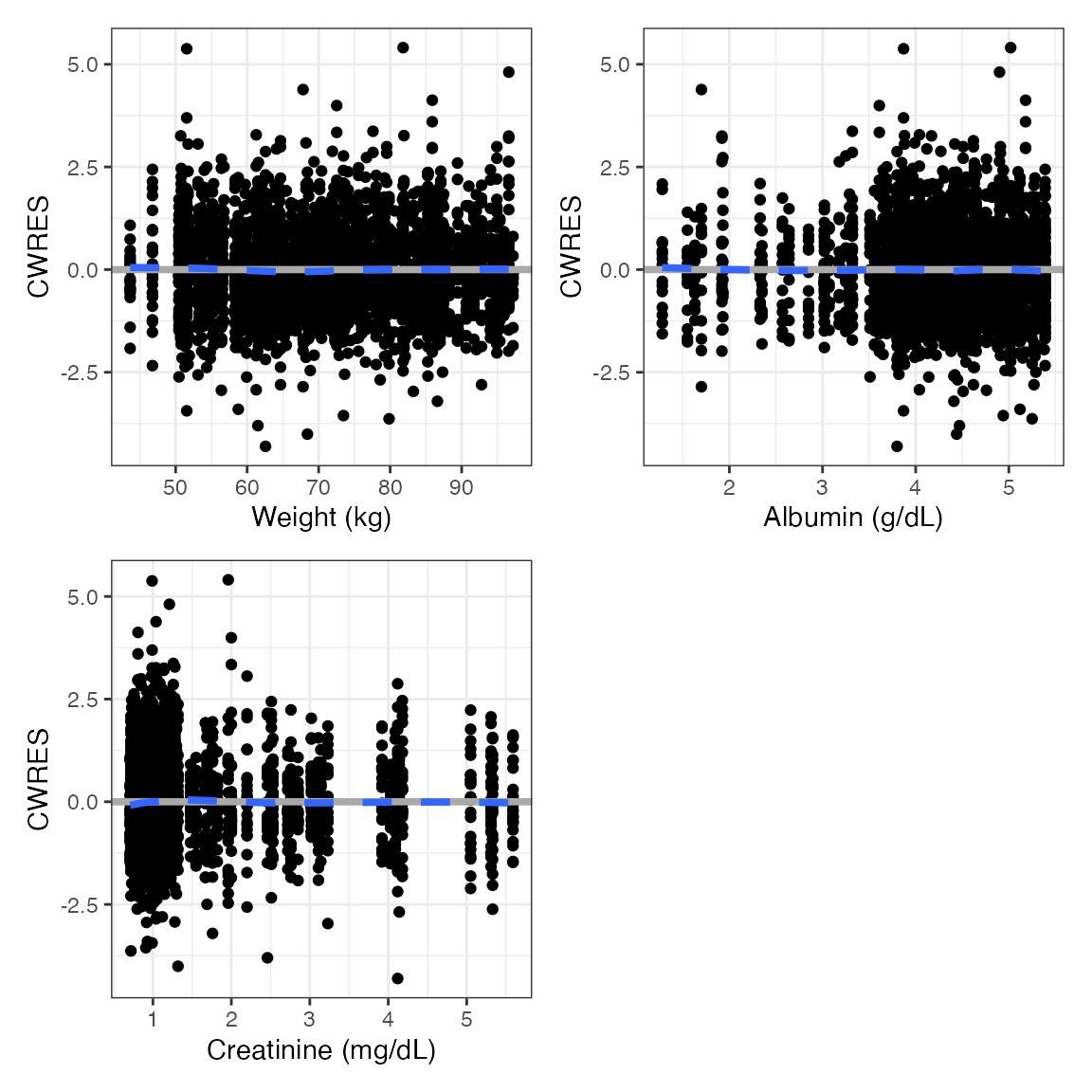
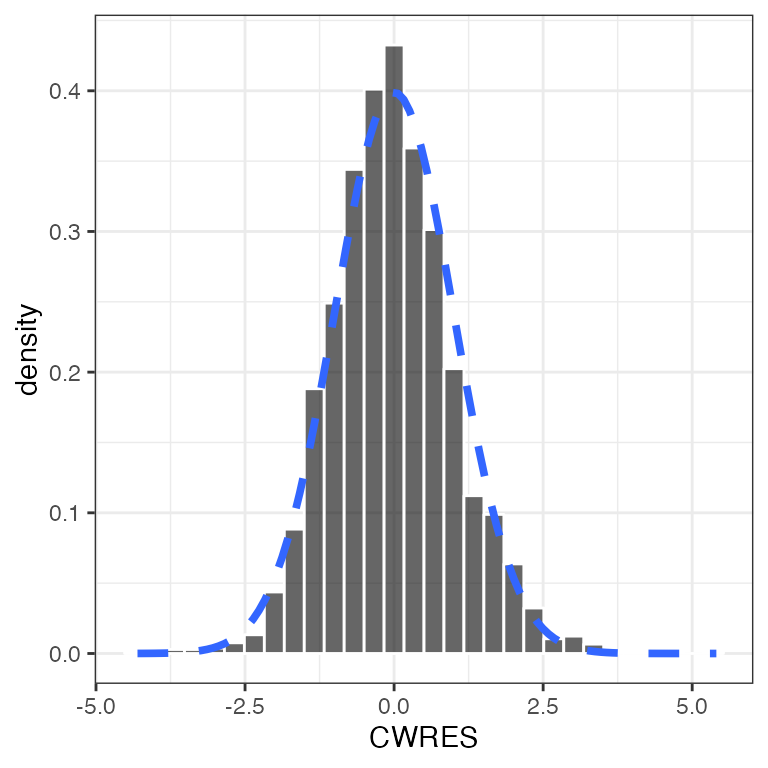
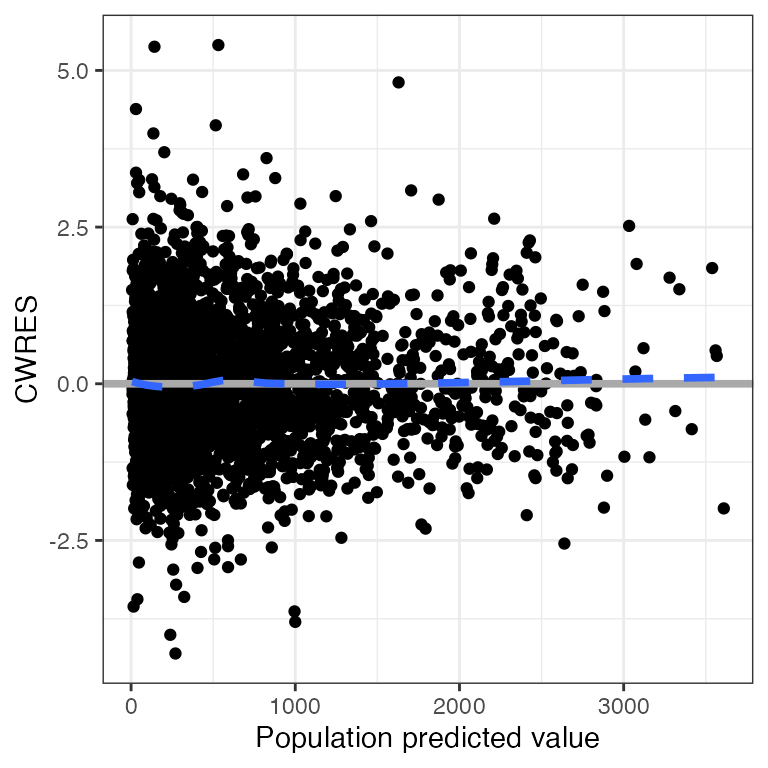
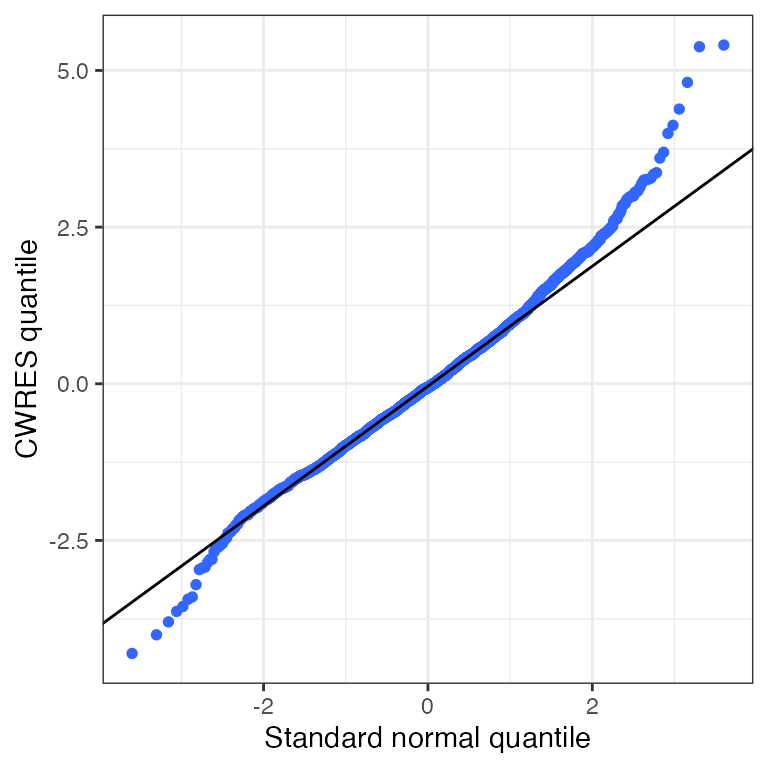
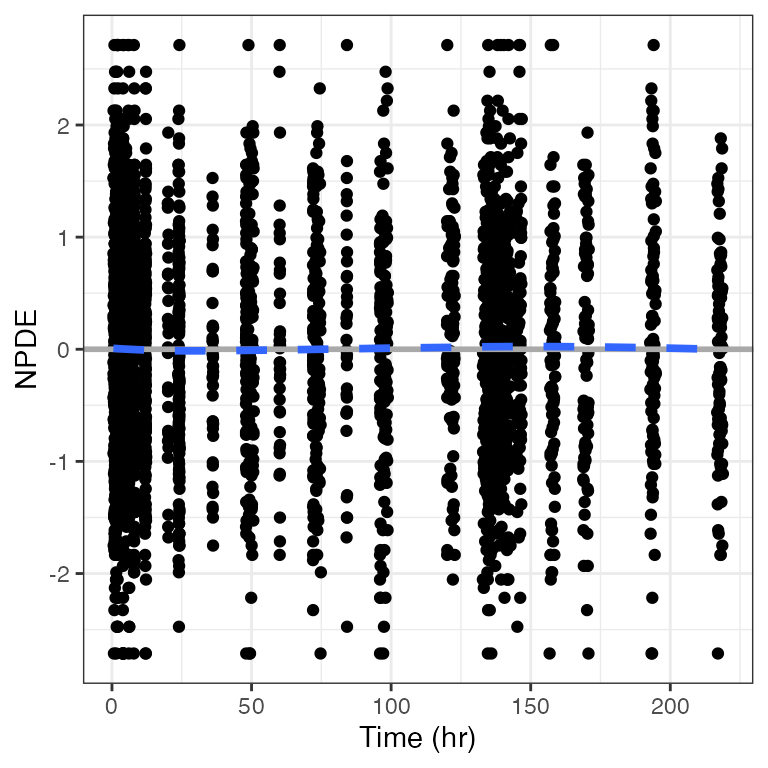
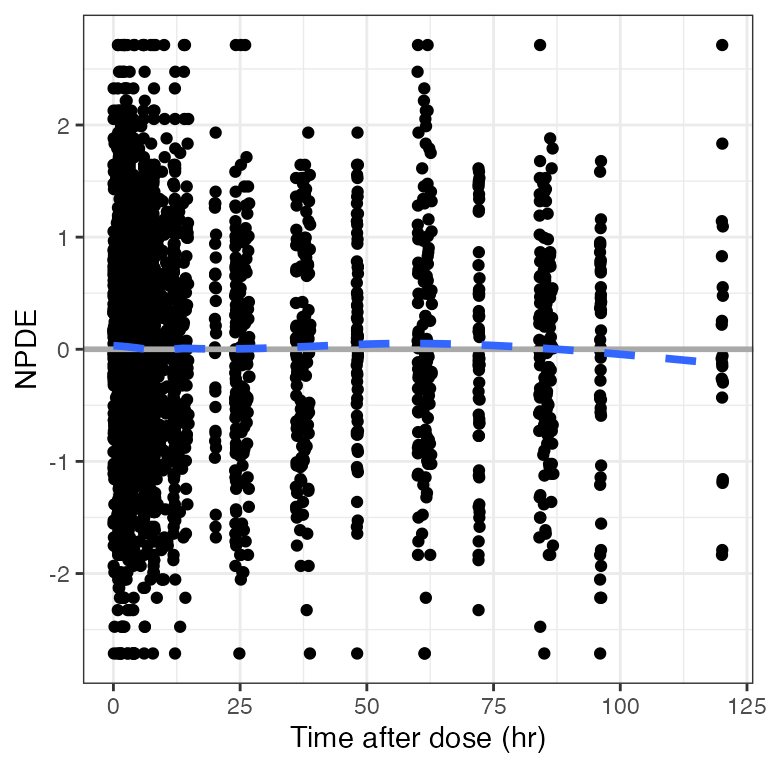
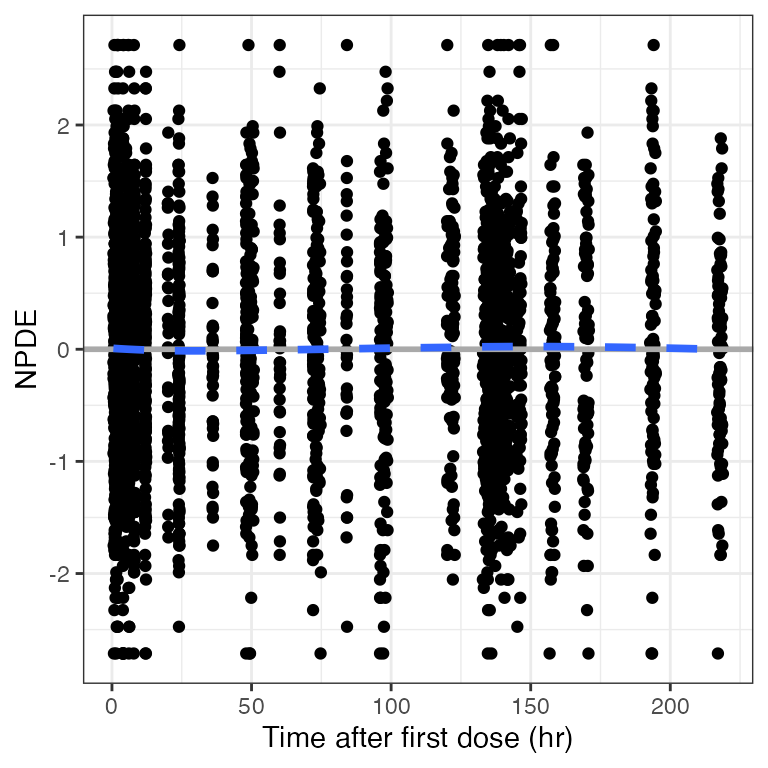
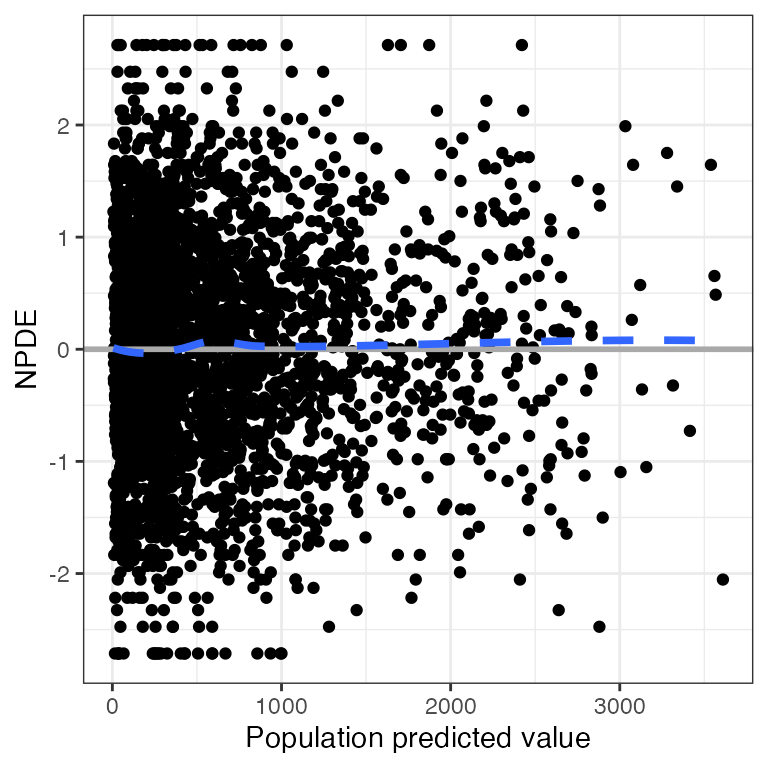
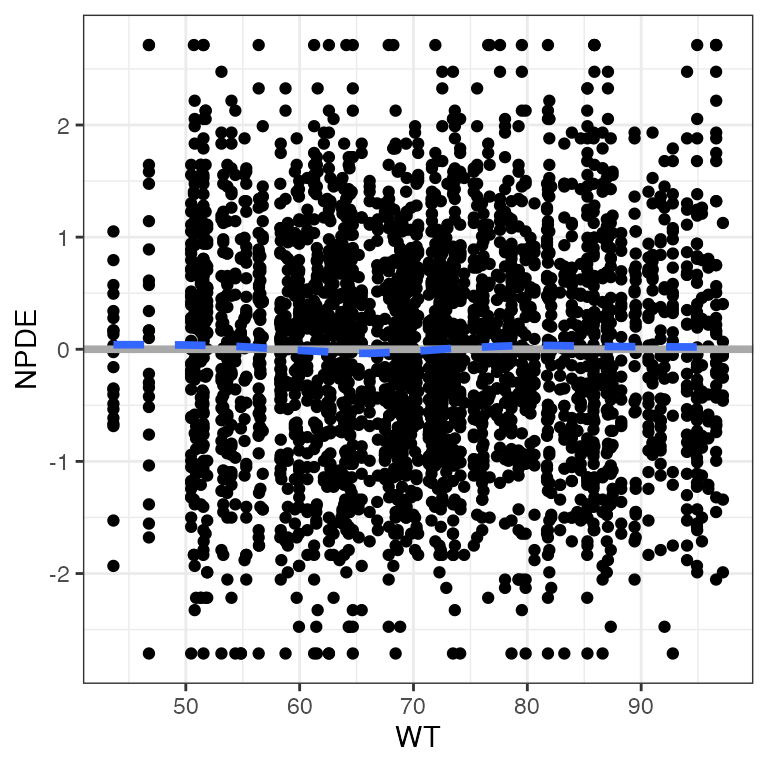
ETA plots
etas <- c("ETA1//ETA-CL", "ETA2//ETA-V2", "ETA3//ETA-KA")
covs <- c("WT//Weight (kg)", "ALB//Albumin (g/dL)", "SCR//Creatinine (mg/dL)")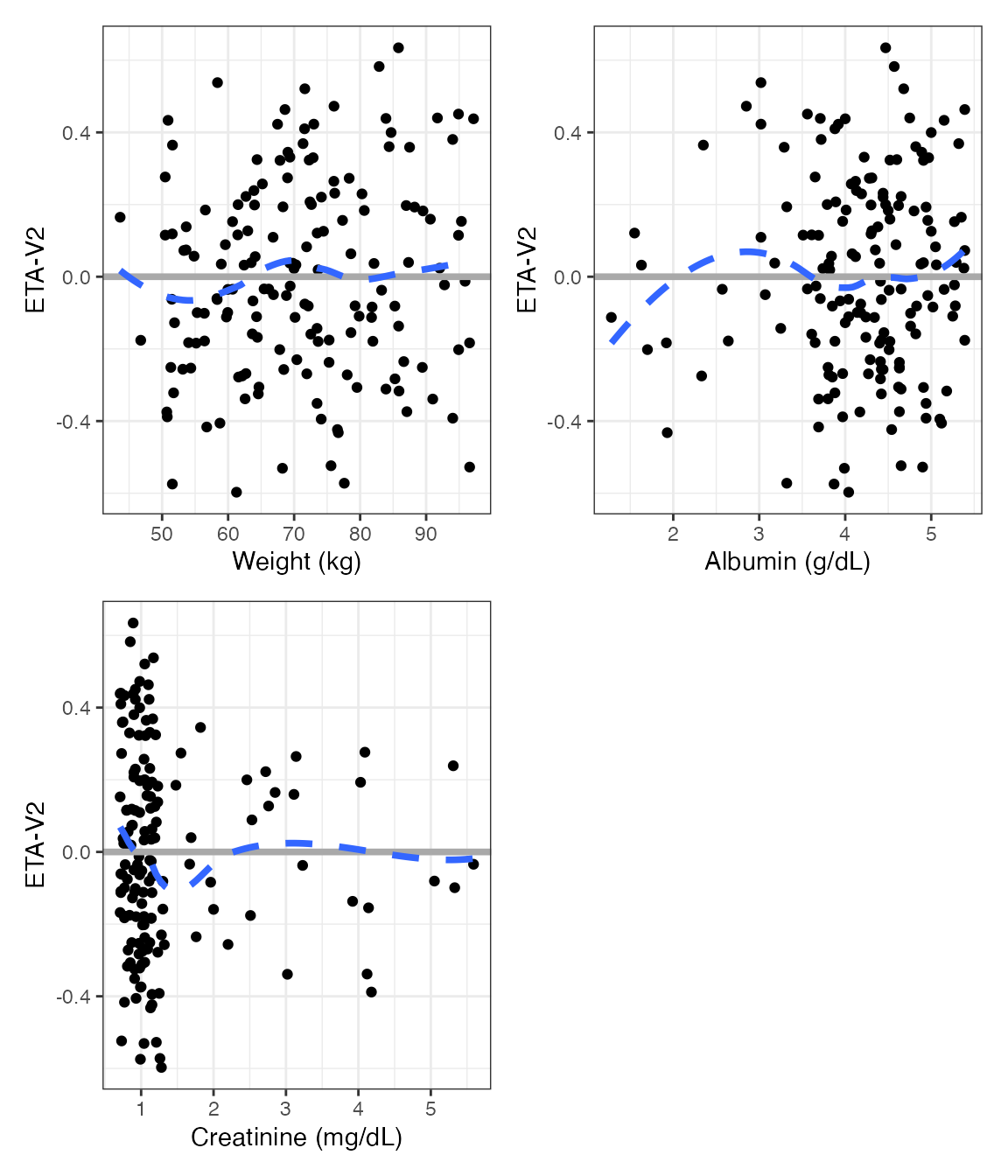
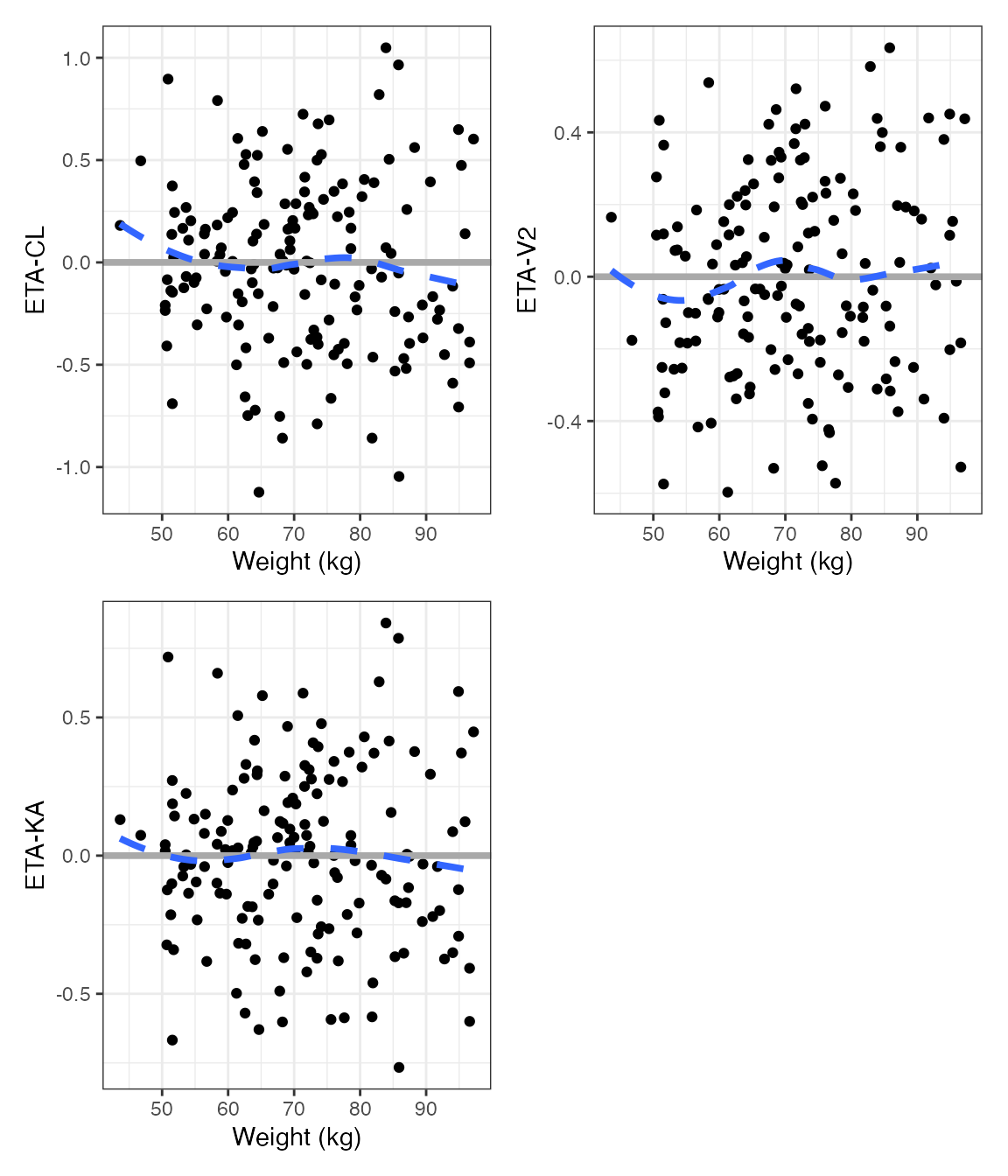
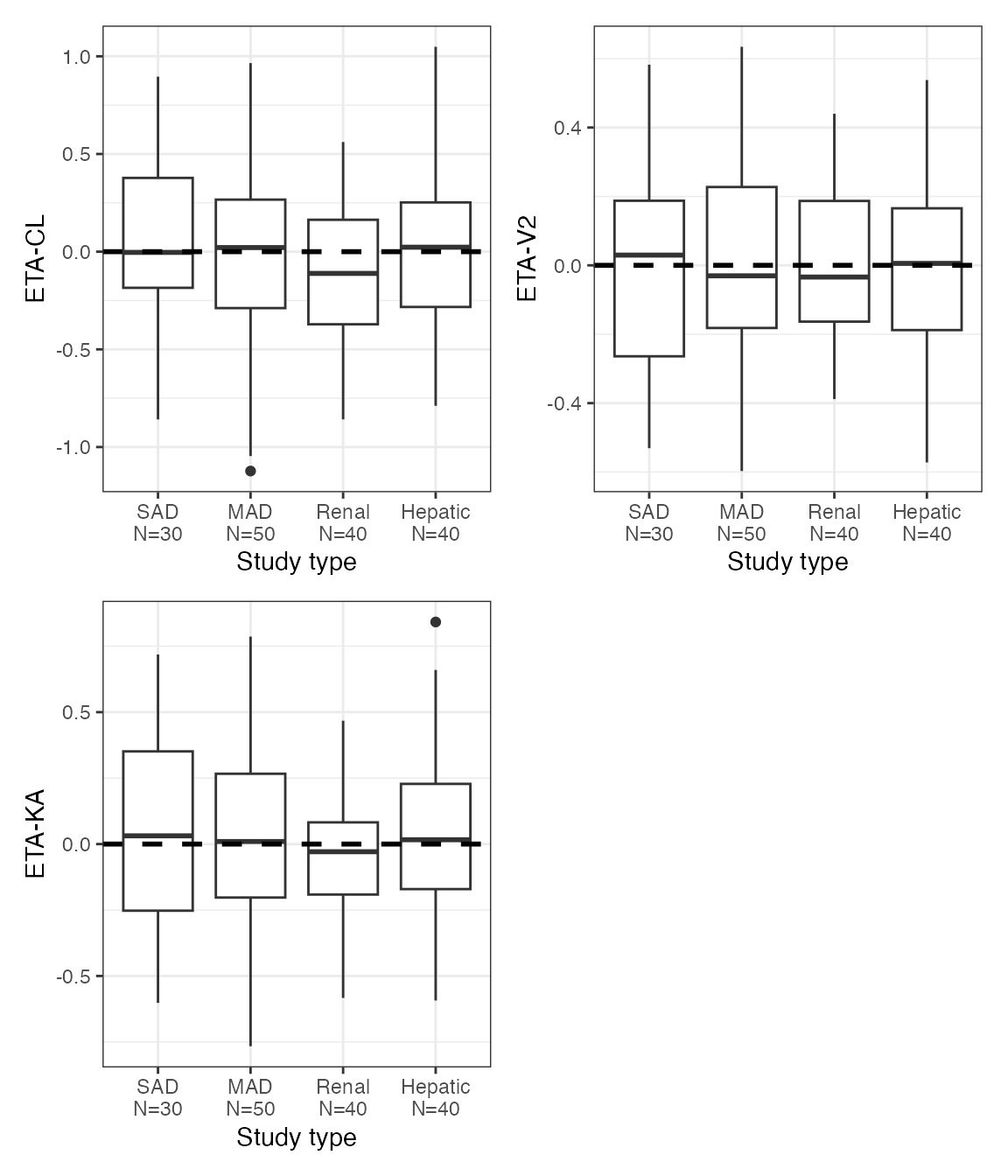
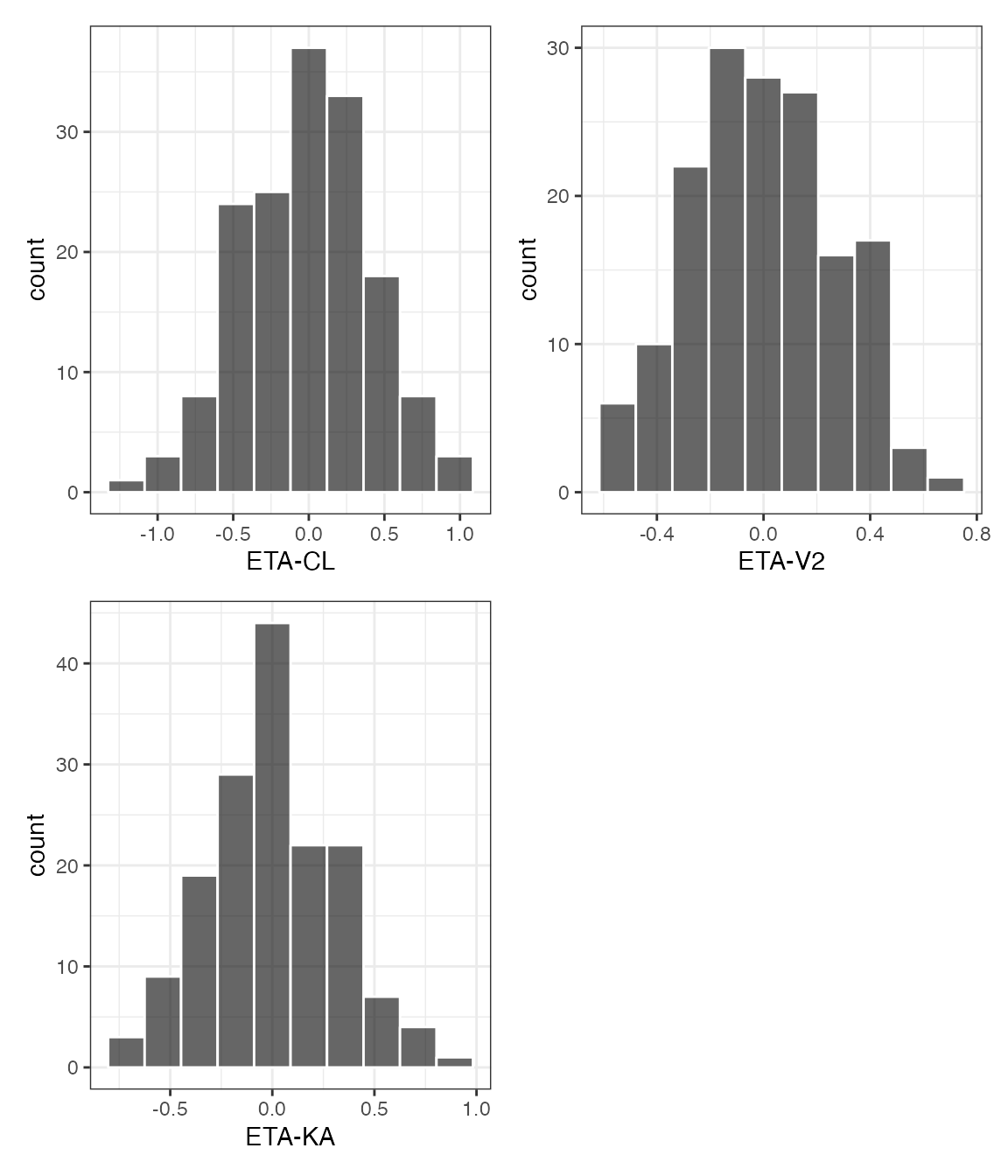
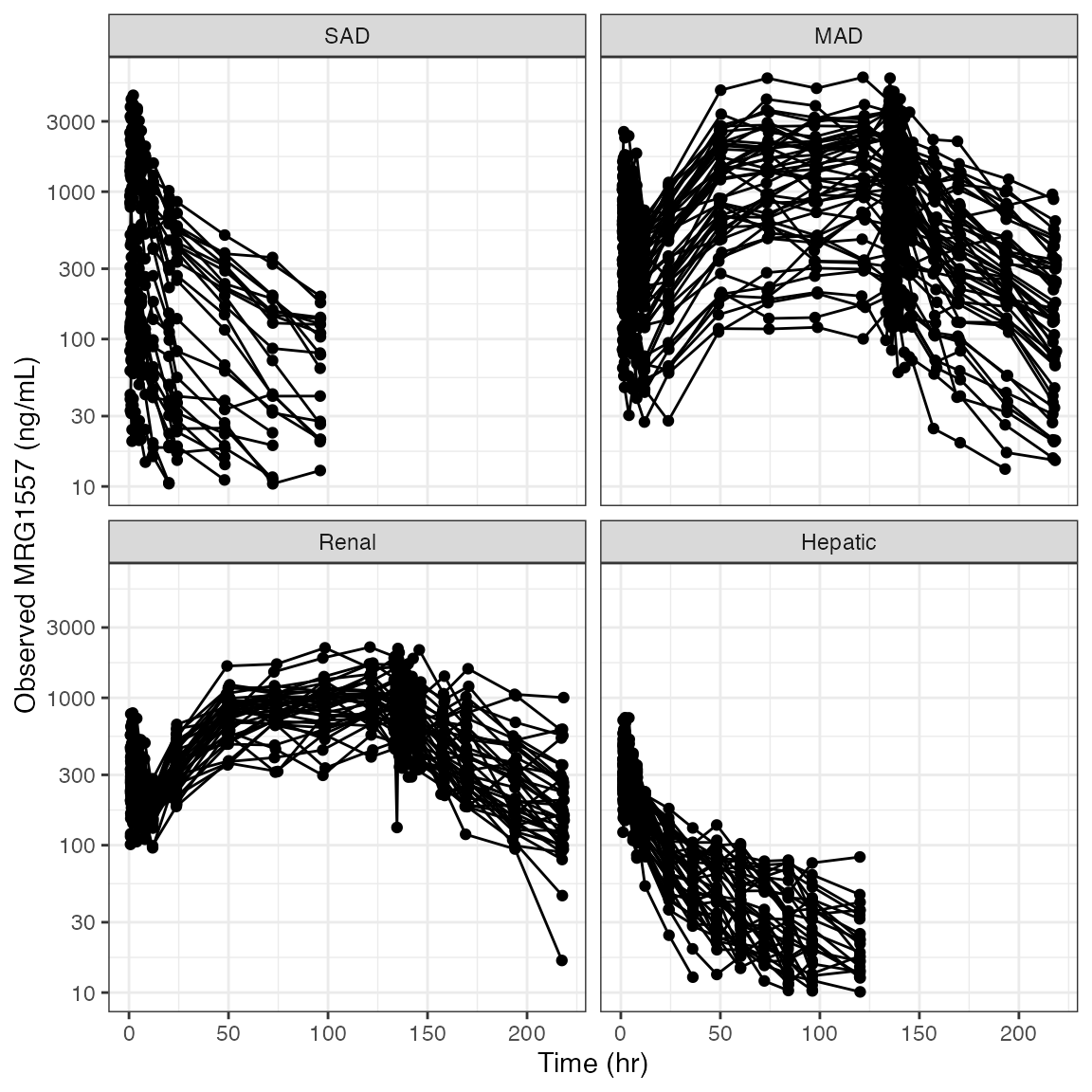
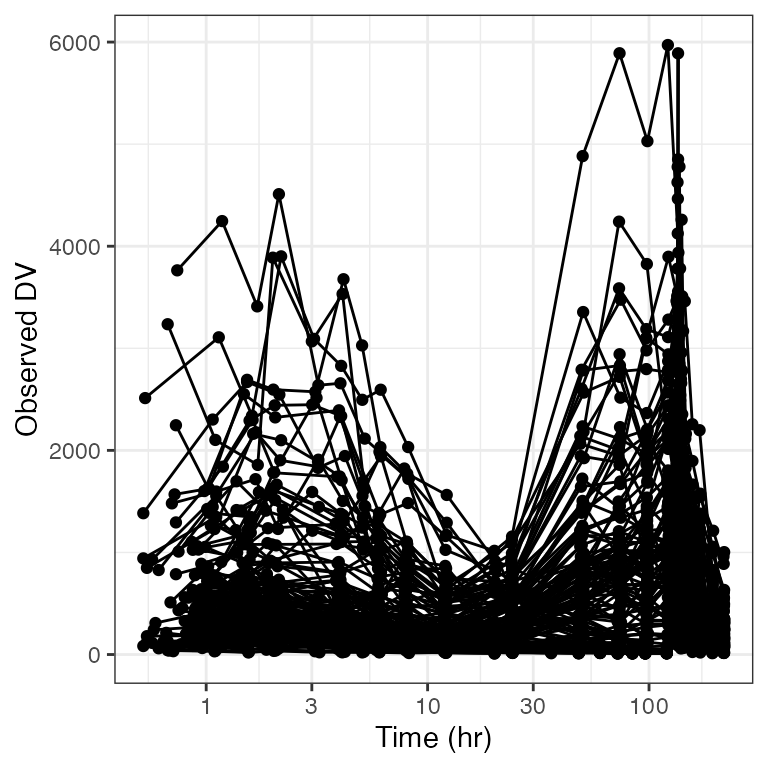
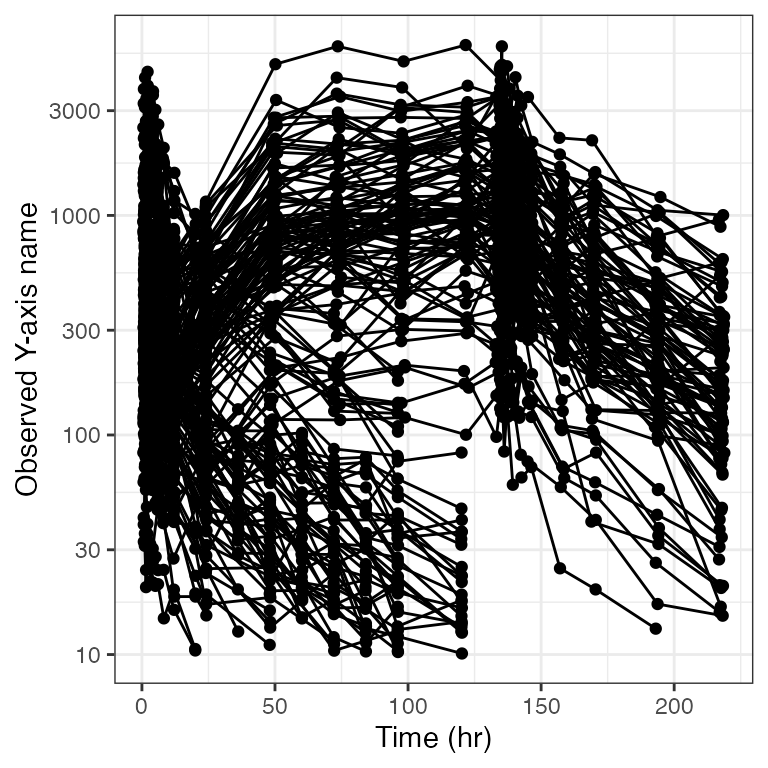
DV versus time (dv_time)
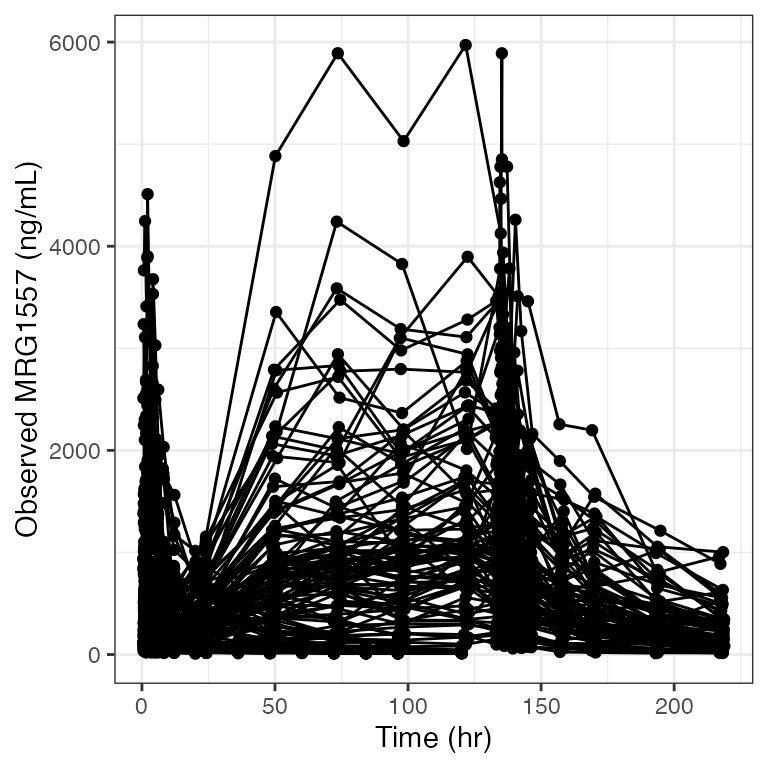
Faceted
dv_time(df, yname="MRG1557 (ng/mL)") + facet_wrap(~DOSE, scales="free_x")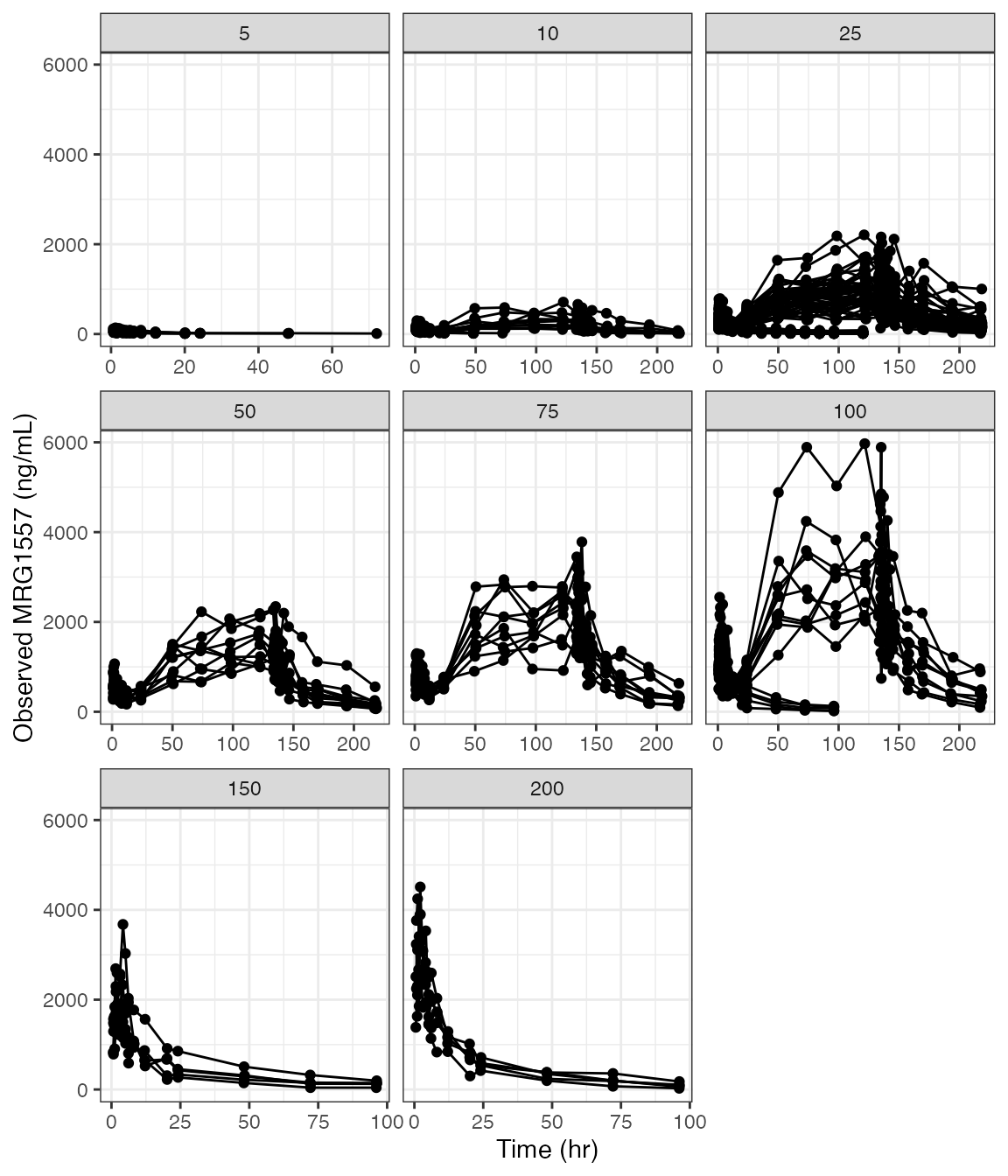
NOTE this will not work as you expect; the labels are wrong.
cwres_cat(df, x = "STUDYc") + facet_wrap(~CPc)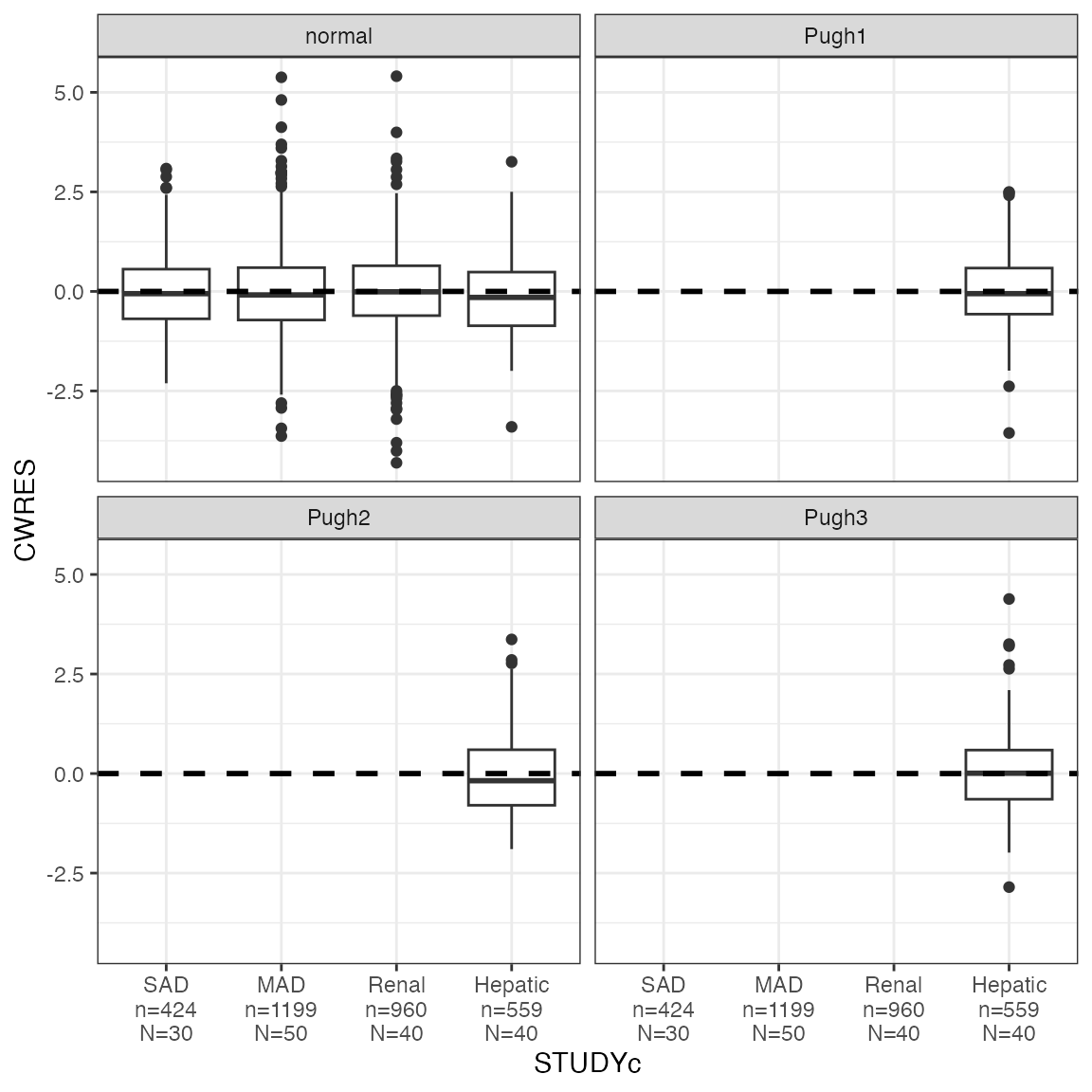
The only way to get this right is
cwres_cat(df, x = "STUDYc", shown=FALSE) + facet_wrap(~CPc)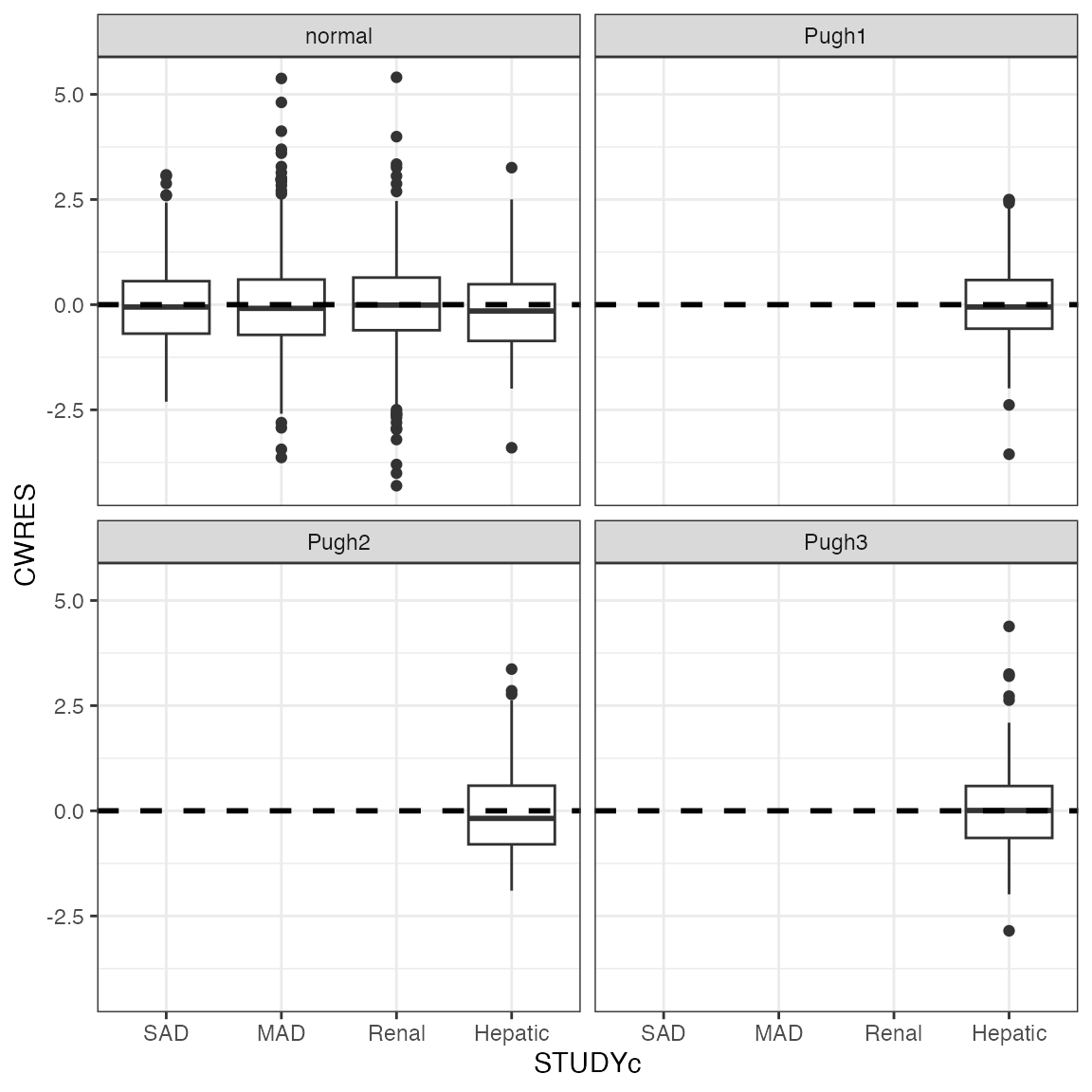
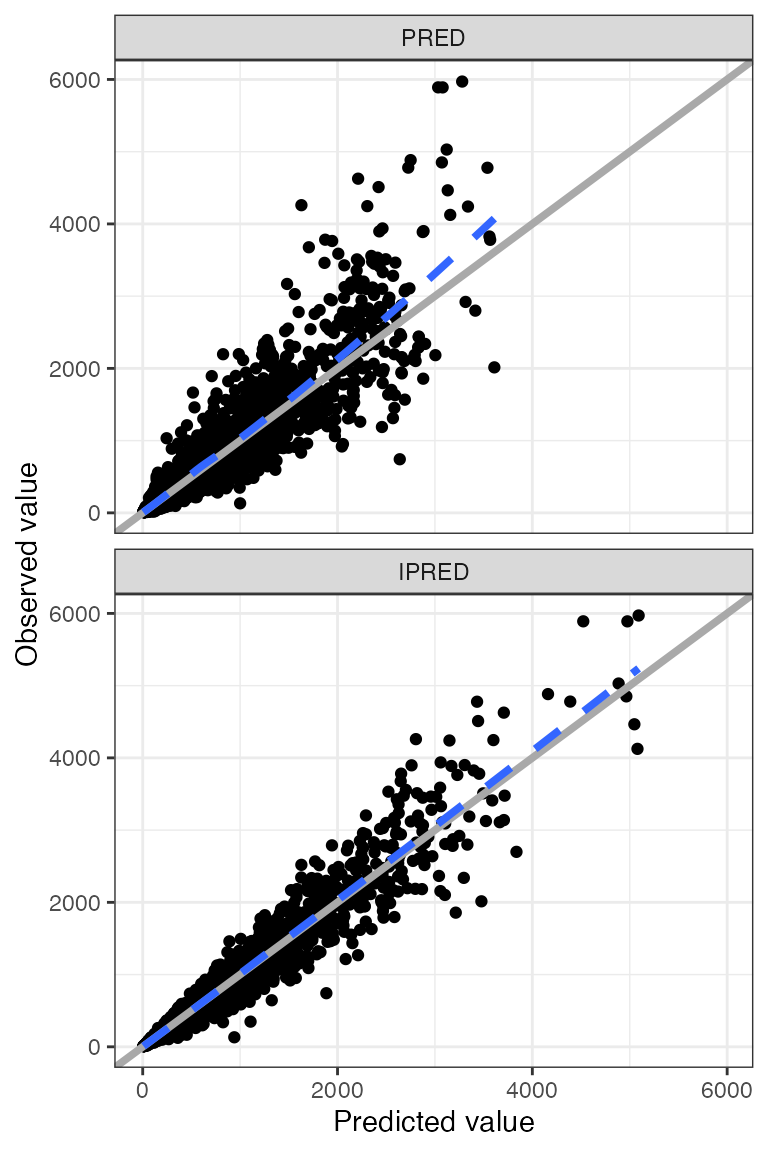
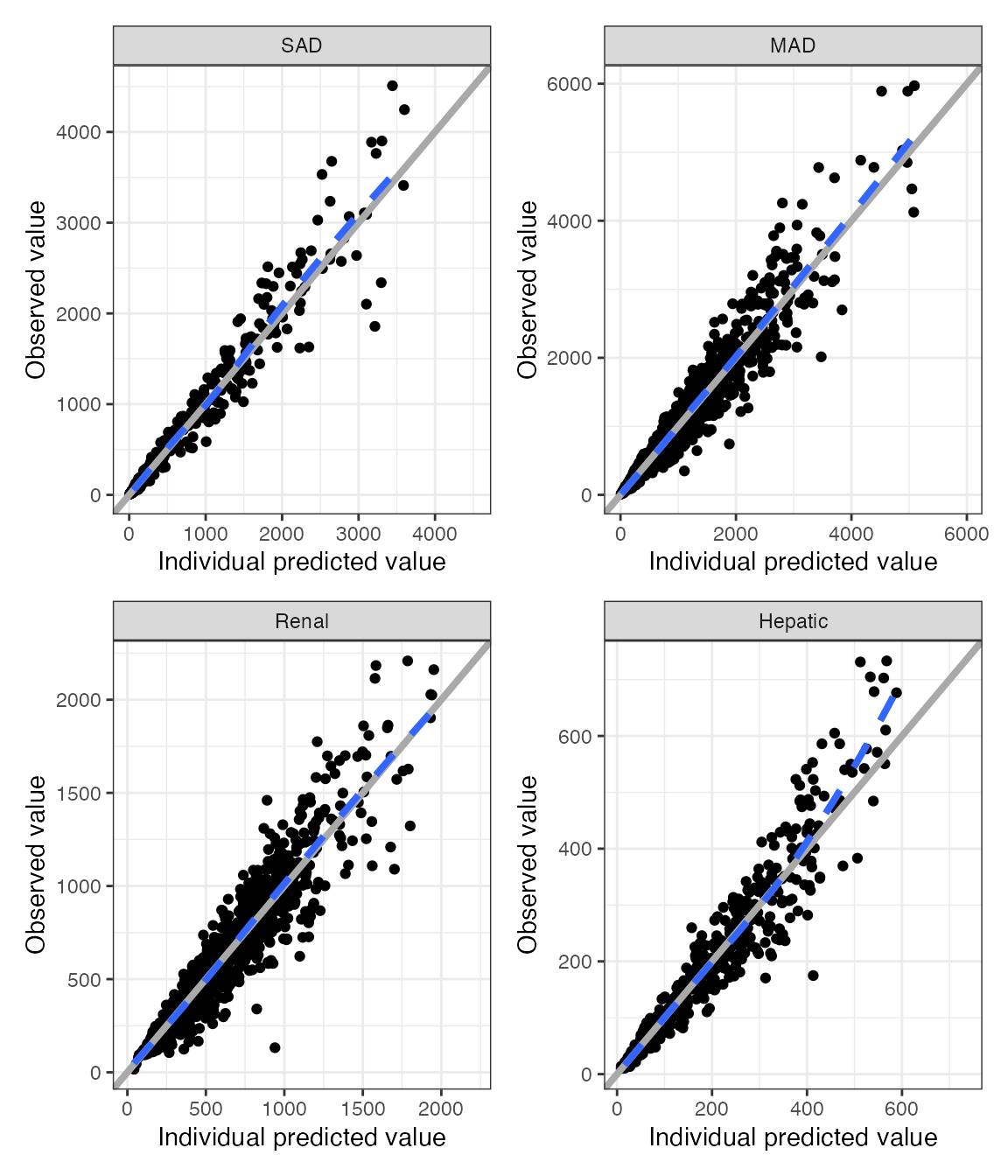
DV-PRED-IPRED
- This returns a list of plots; we show only one here (the first 9 IDs) as an example
dd1 <- filter(df, ID <= 15)
dv_pred_ipred(dd1, nrow = 3, ncol = 3, ylab = "Concentration (ng/mL)", log_y=TRUE). $`1`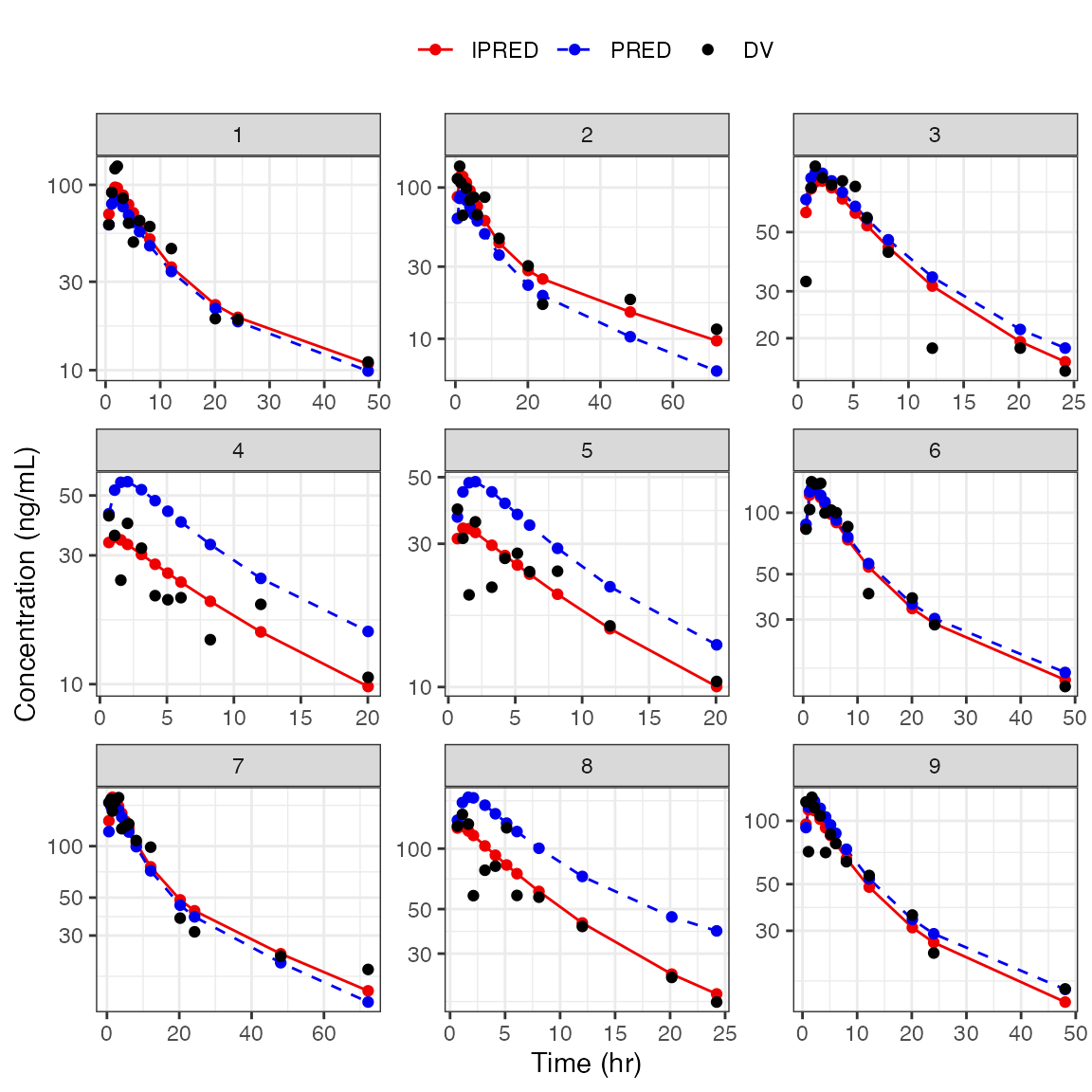
.
. $`2`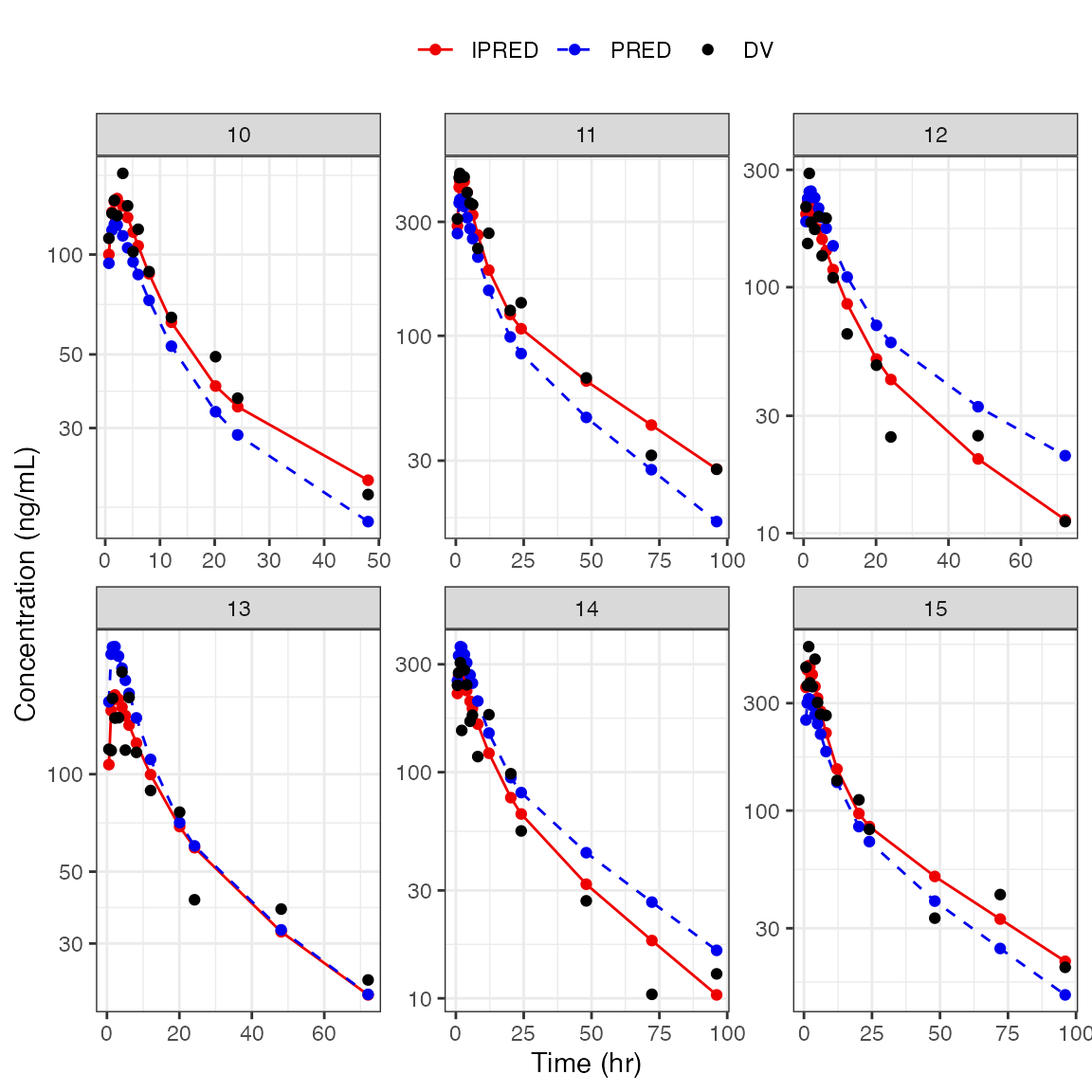
Wrapped plots
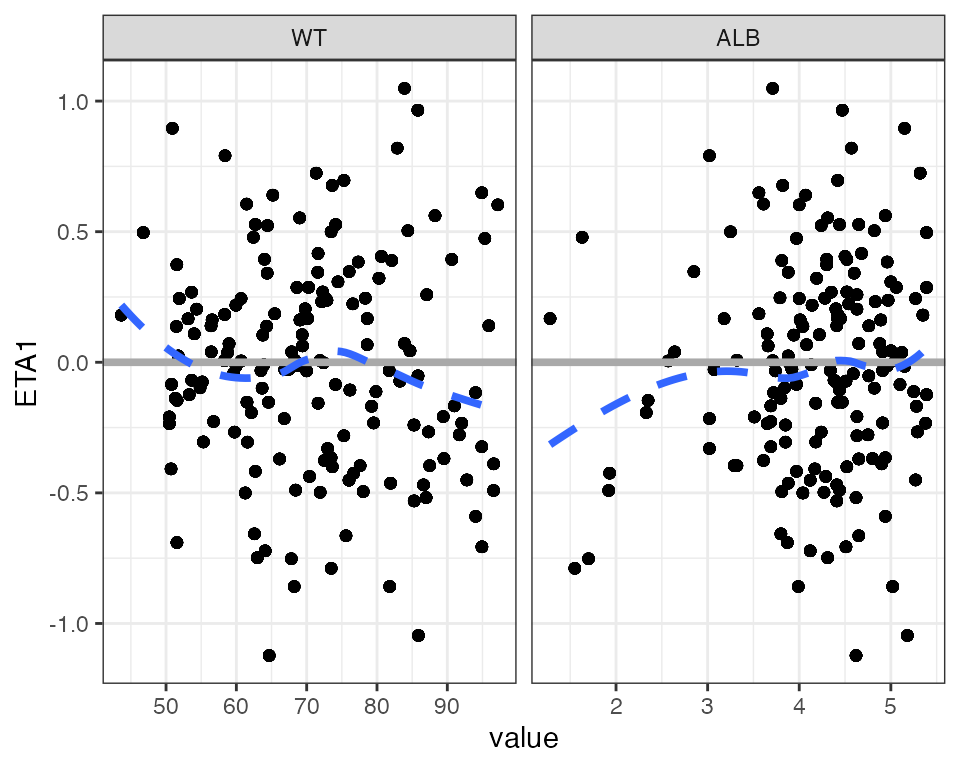
Continuous on continuous
wrap_cont_cont(df, y = "CWRES" , x = c("WT", "CRCL", "AAG"), ncol = 2, scales="free_x") 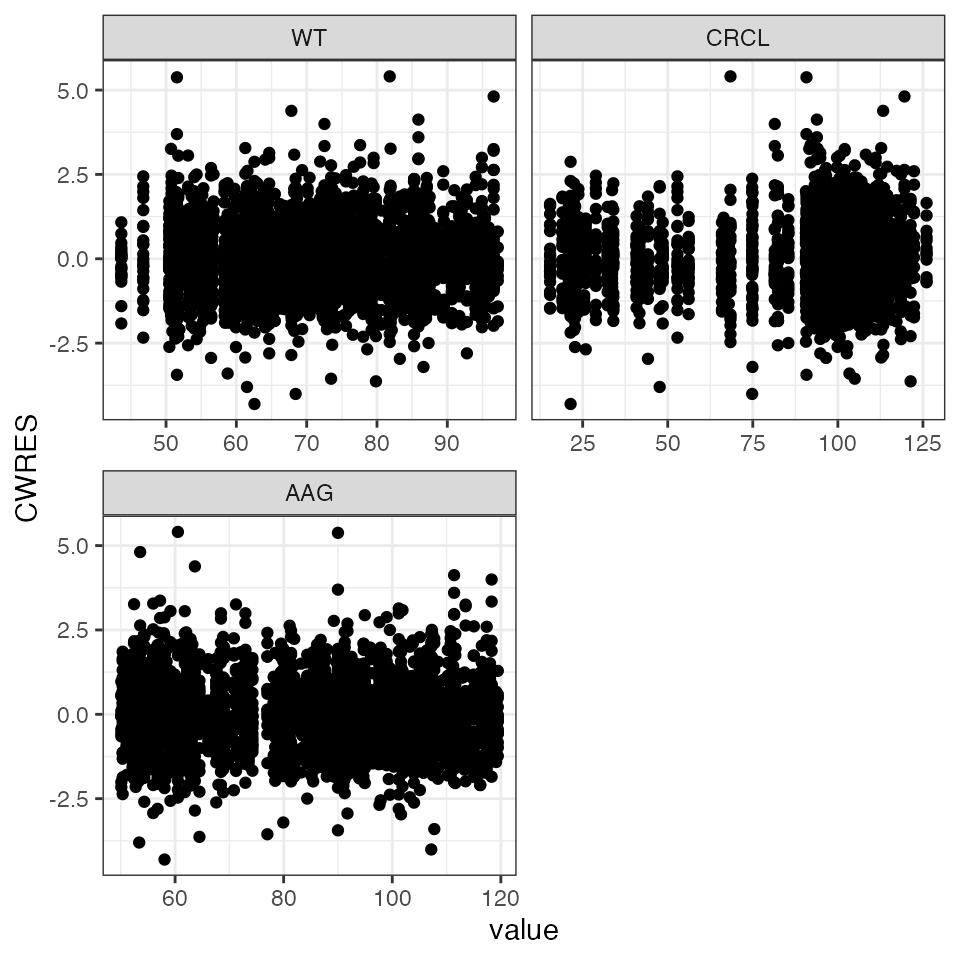
Use labels in the strip
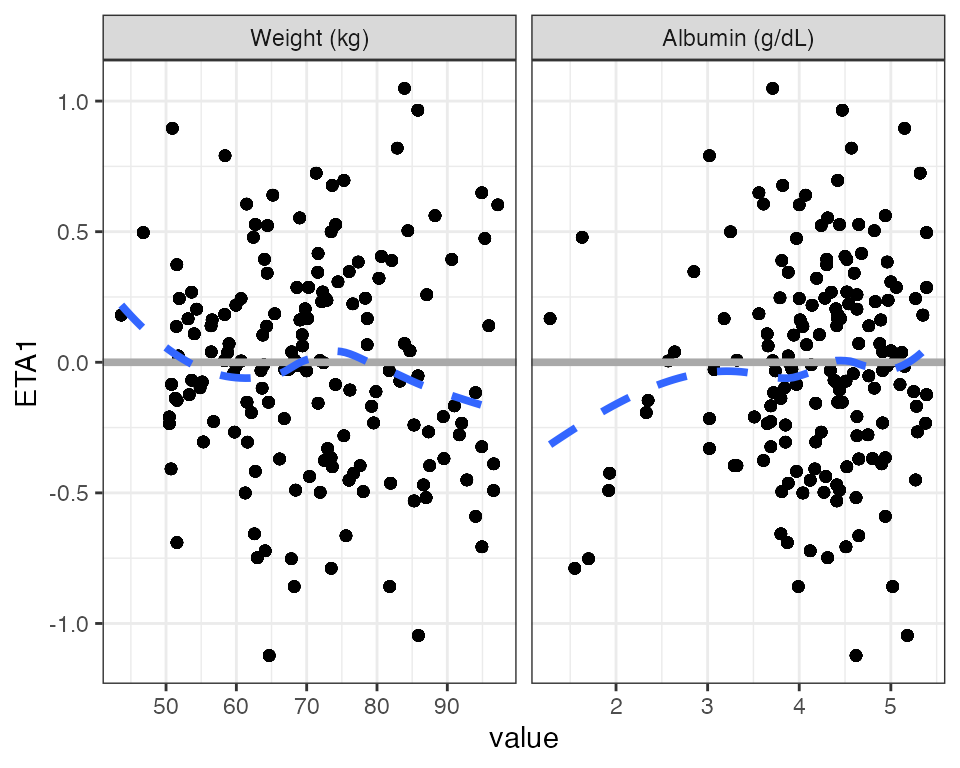
wrap_eta_cont(
df,
y = "ETA1",
x = c("WT//Weight (kg)", "ALB//Albumin (g/dL)"),
scales="free_x",
use_labels=TRUE
)
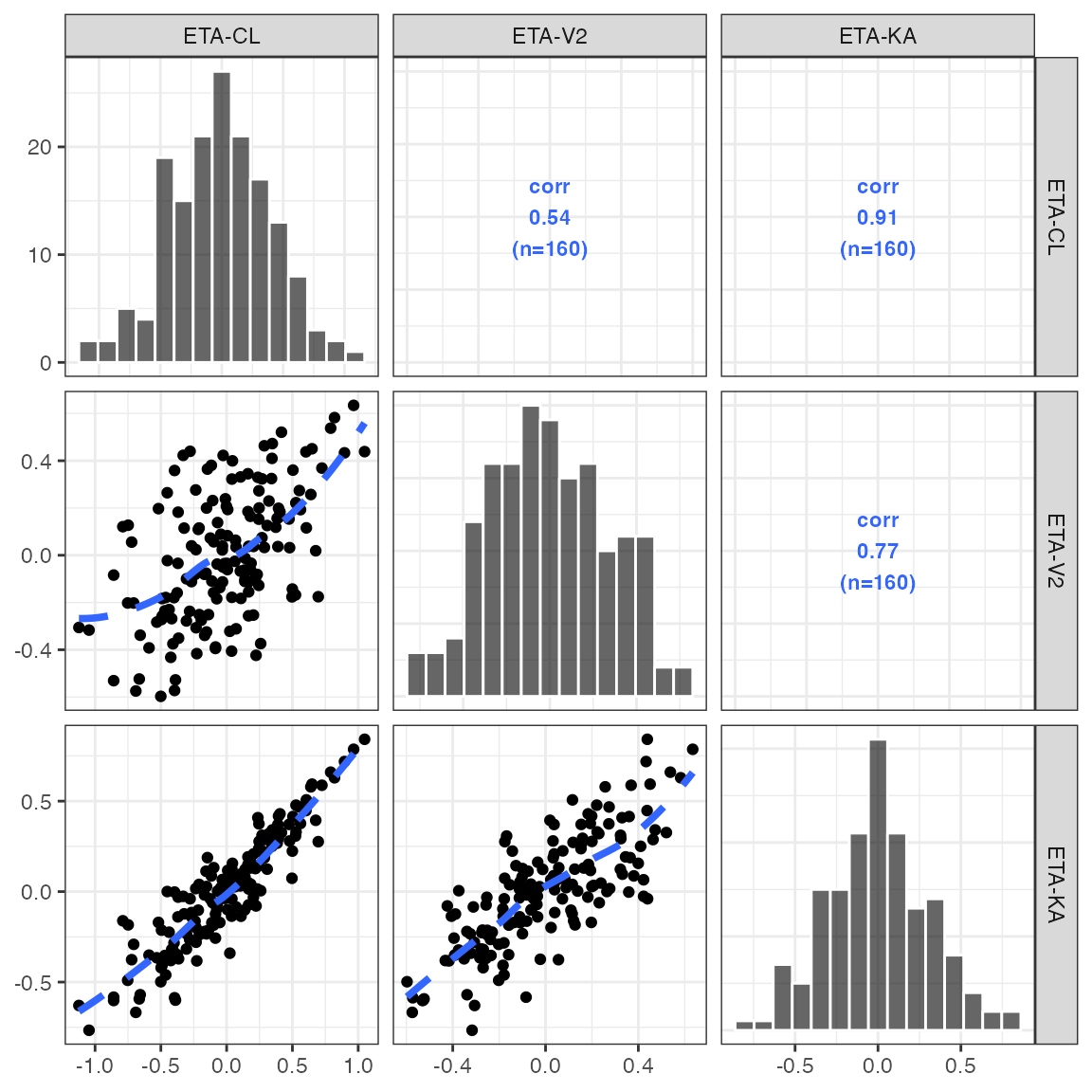
Pairs plots
This is a simple wrapper around GGally::ggpairs with
some customizations that have been developed internally at Metrum over
the years.
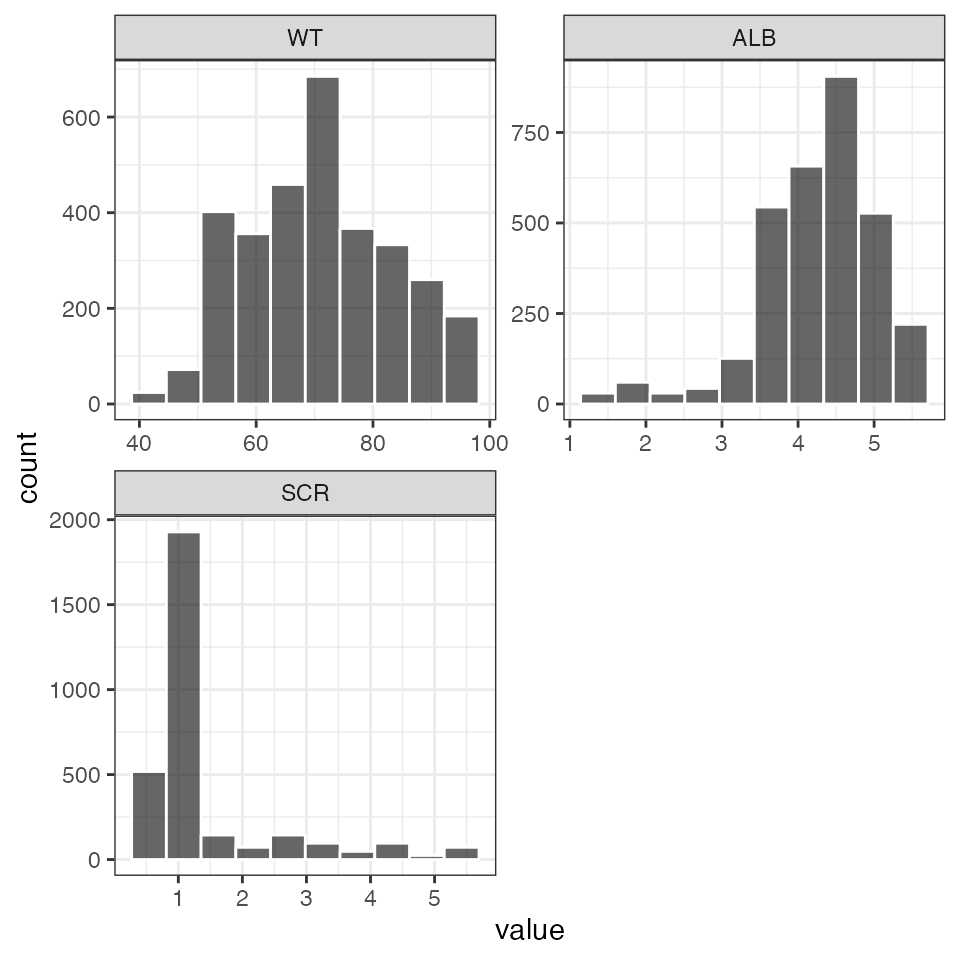
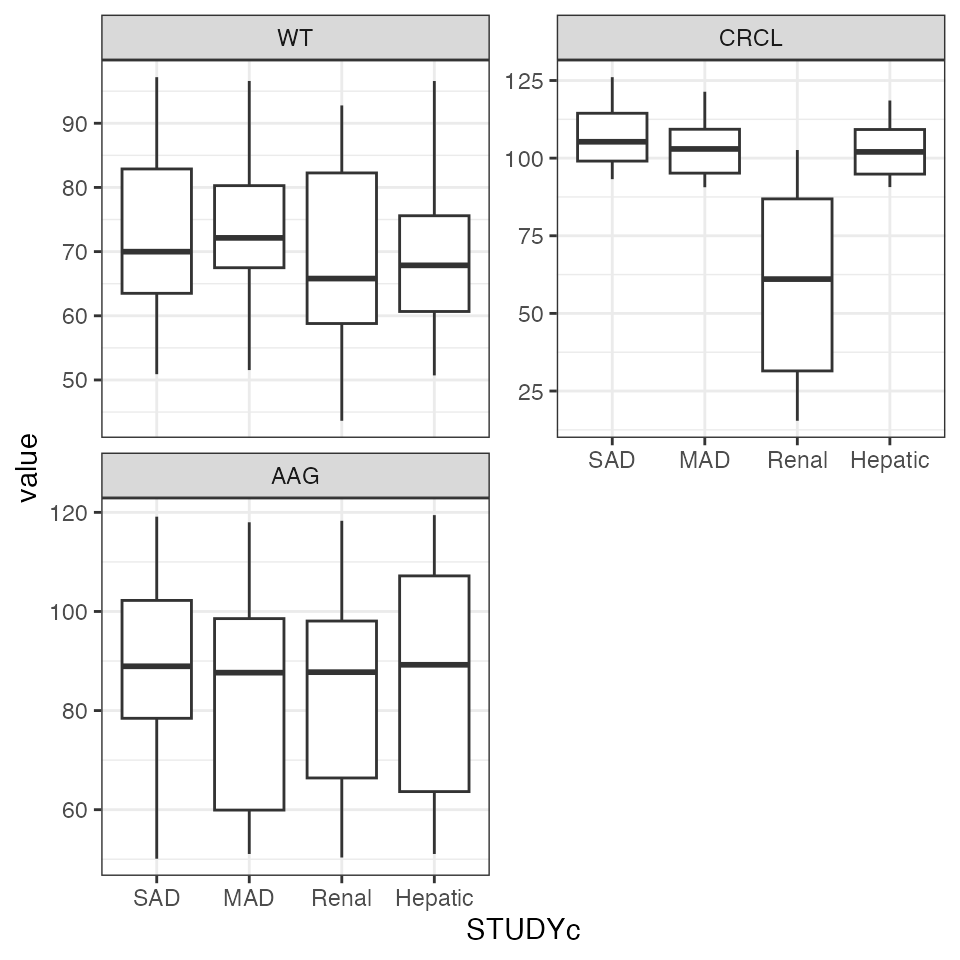
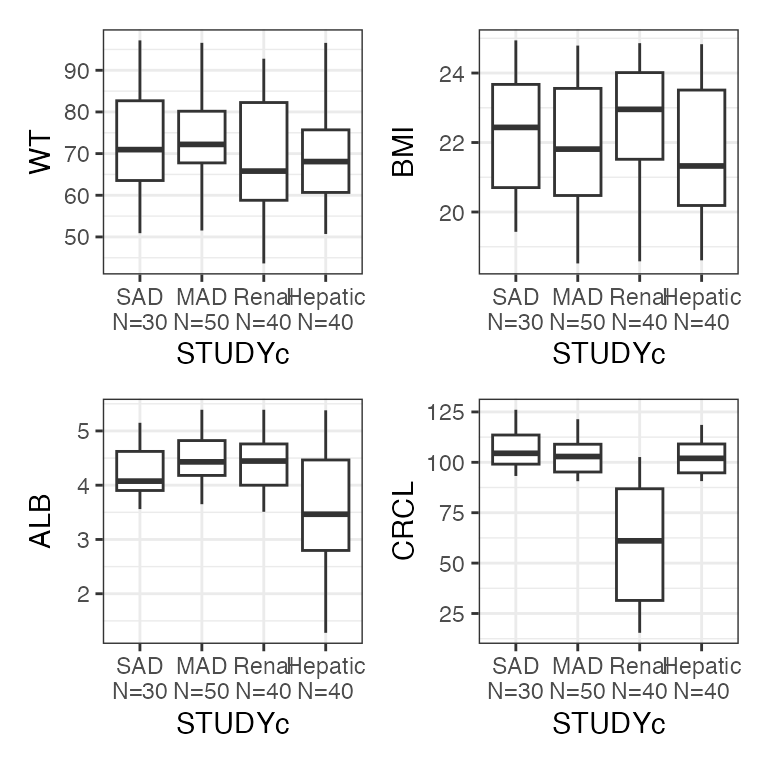
pairs_plot(id, c("WT//Weight", "ALB//Albumin", "SCR//Serum creat"))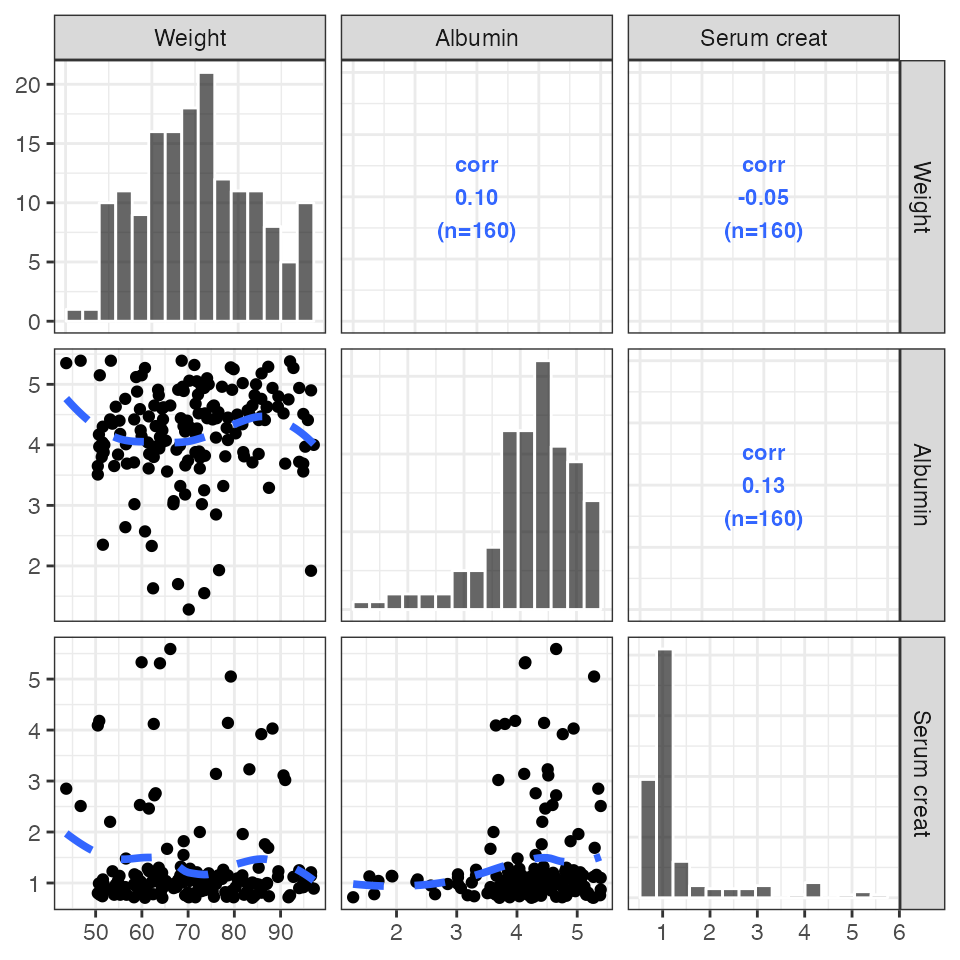
Customized lower triangle
Pass a function that customizes the scatter plots on the lower triangle. This function should accept a gg object and add a geom to it
my_lower <- function(p) {
p + geom_point(aes(color = STUDYc)) +
geom_smooth(se = FALSE, color = "black")
}
pairs_plot(id, c("WT", "ALB"), lower_plot = my_lower)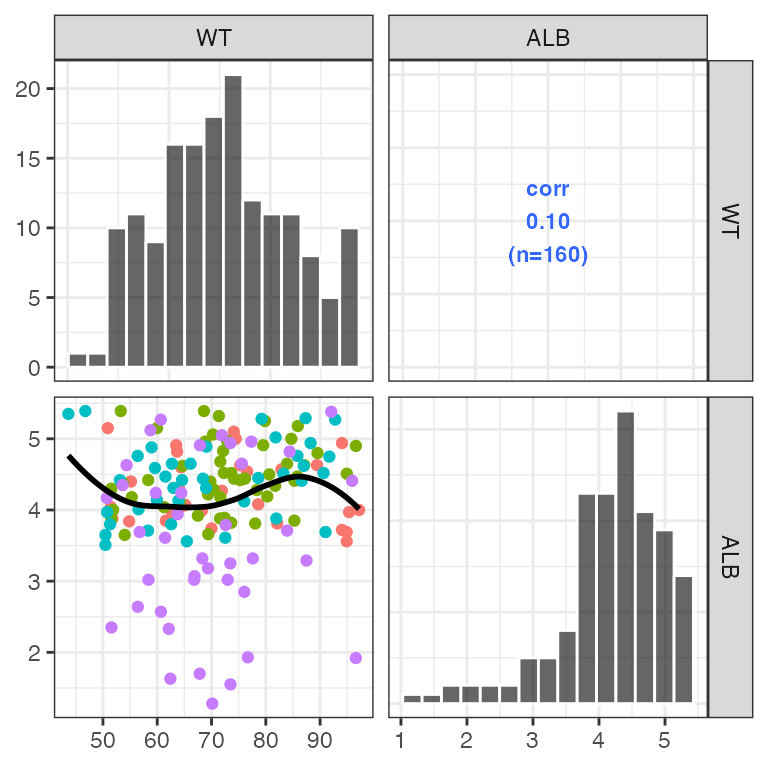
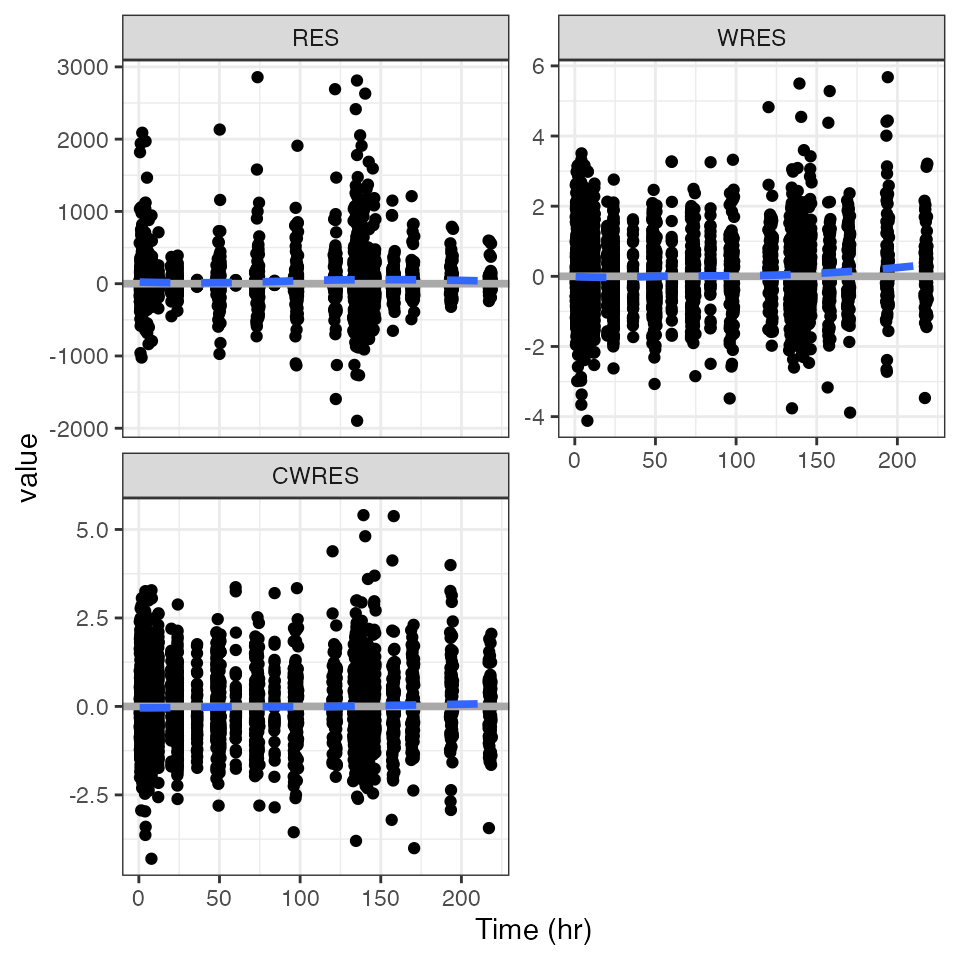
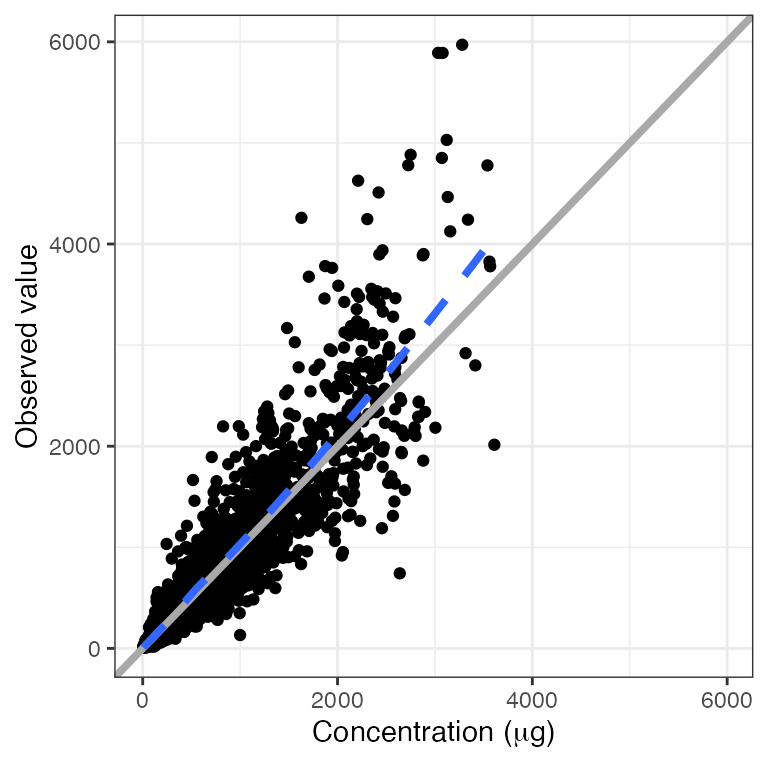
Vectorized plots
pm_scatter(df, x = "TIME", y = c("RES", "WRES", "CWRES")). $RES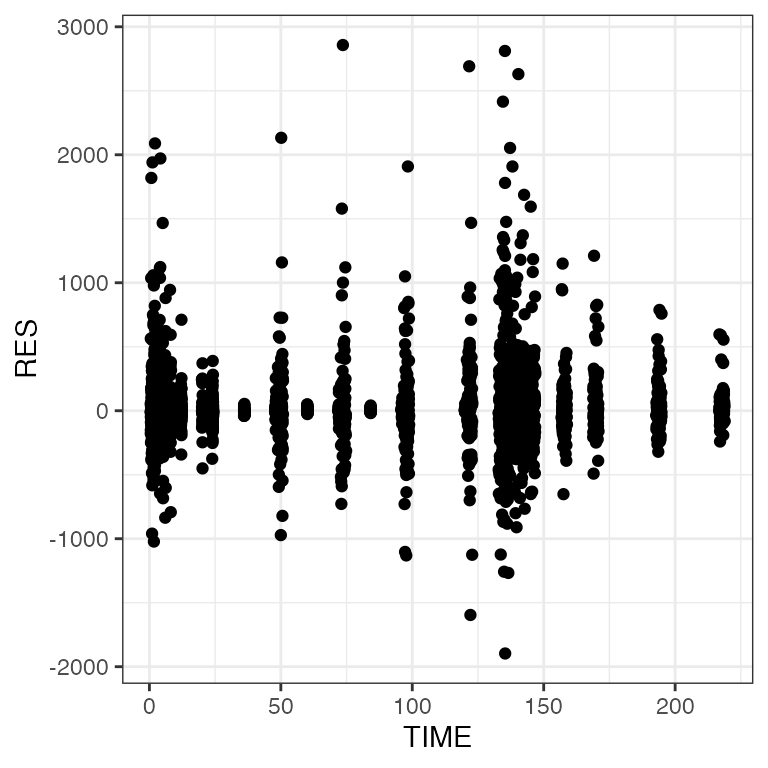
.
. $WRES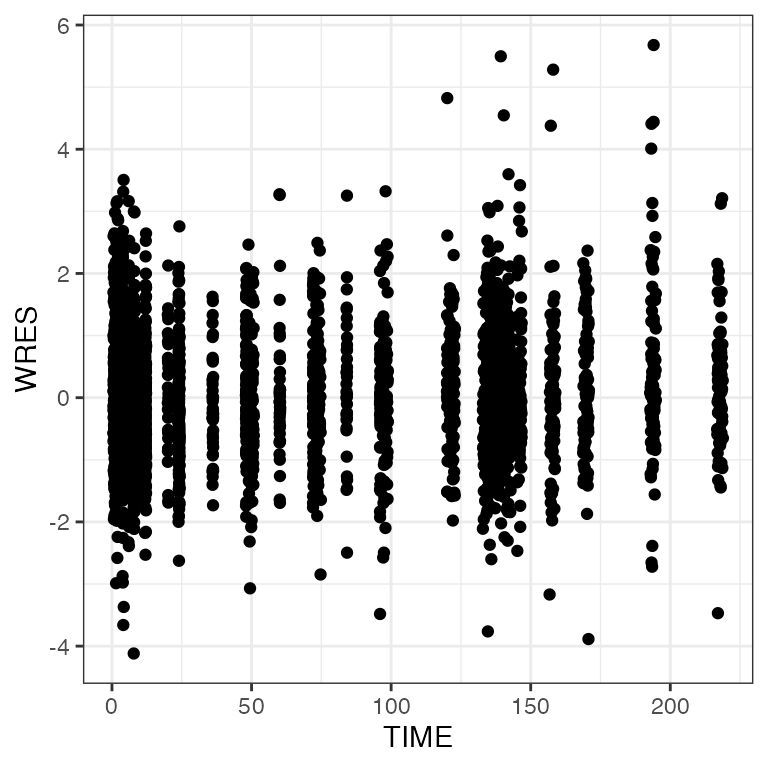
.
. $CWRES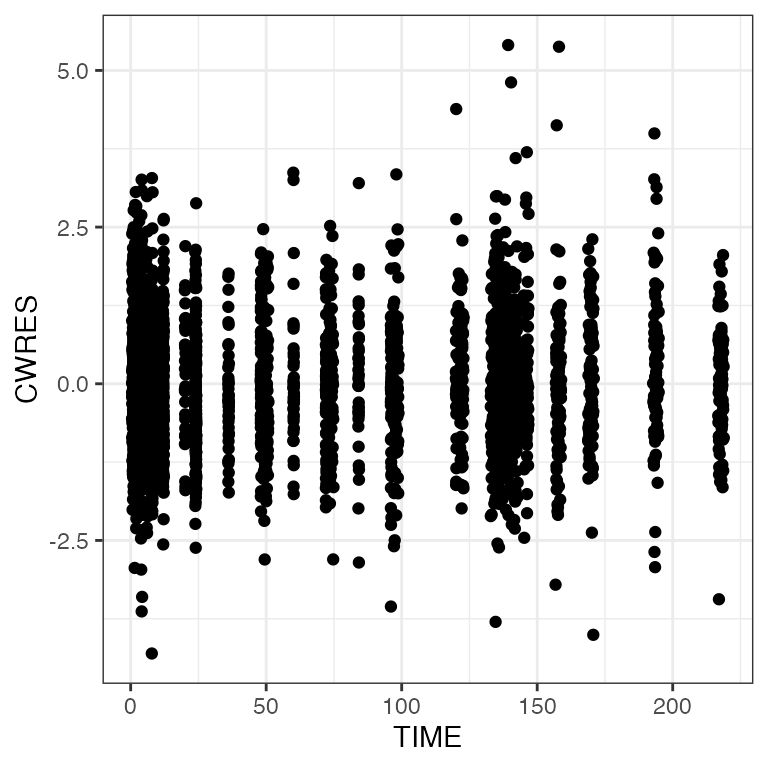
Some customization
Latex in pairs plot
data <- dplyr::tibble(m = rnorm(100), s = rnorm(100), n = rnorm(100))
x <- c("m//$\\mu$", "s//$\\sigma$", "n//$\\nu$")
pairs_plot(data,x)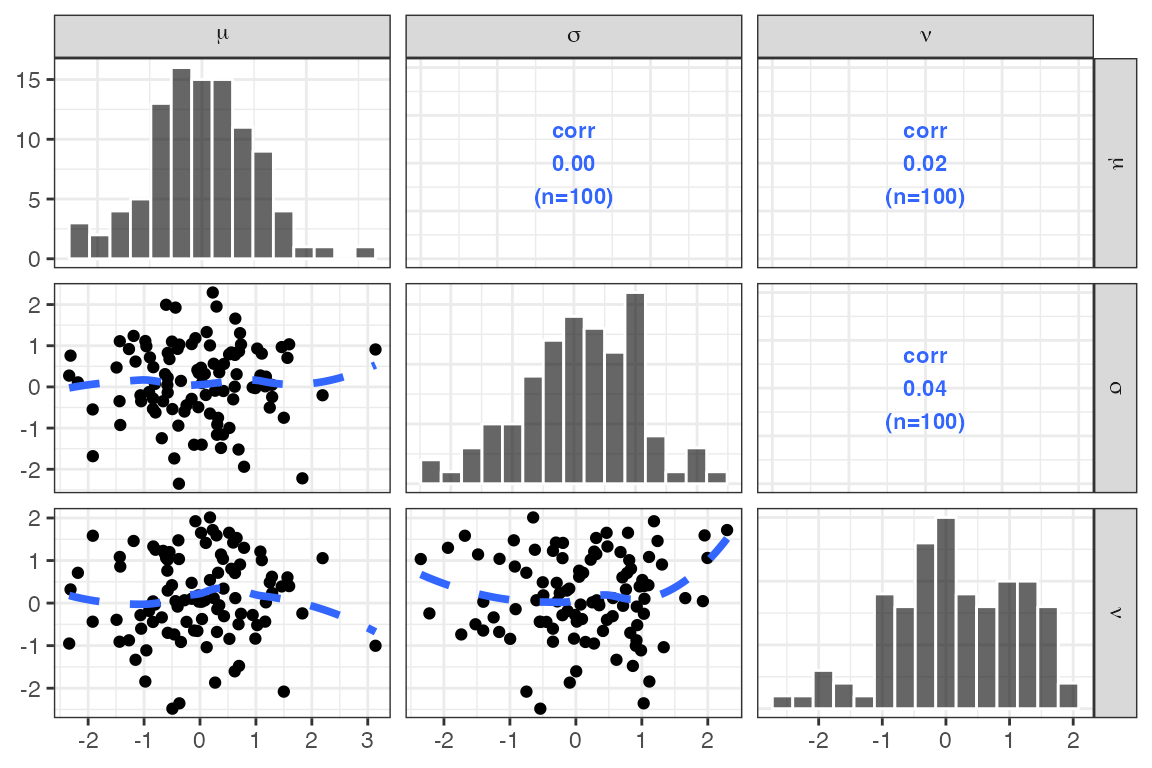
Latex in wrapped plots
y <- c("WT//Weight (kg)", "BMI//BMI (kg/m$^2$)", "SCR//SCR (g/dL)")
wrap_cont_time(df, y = y, use_labels=TRUE)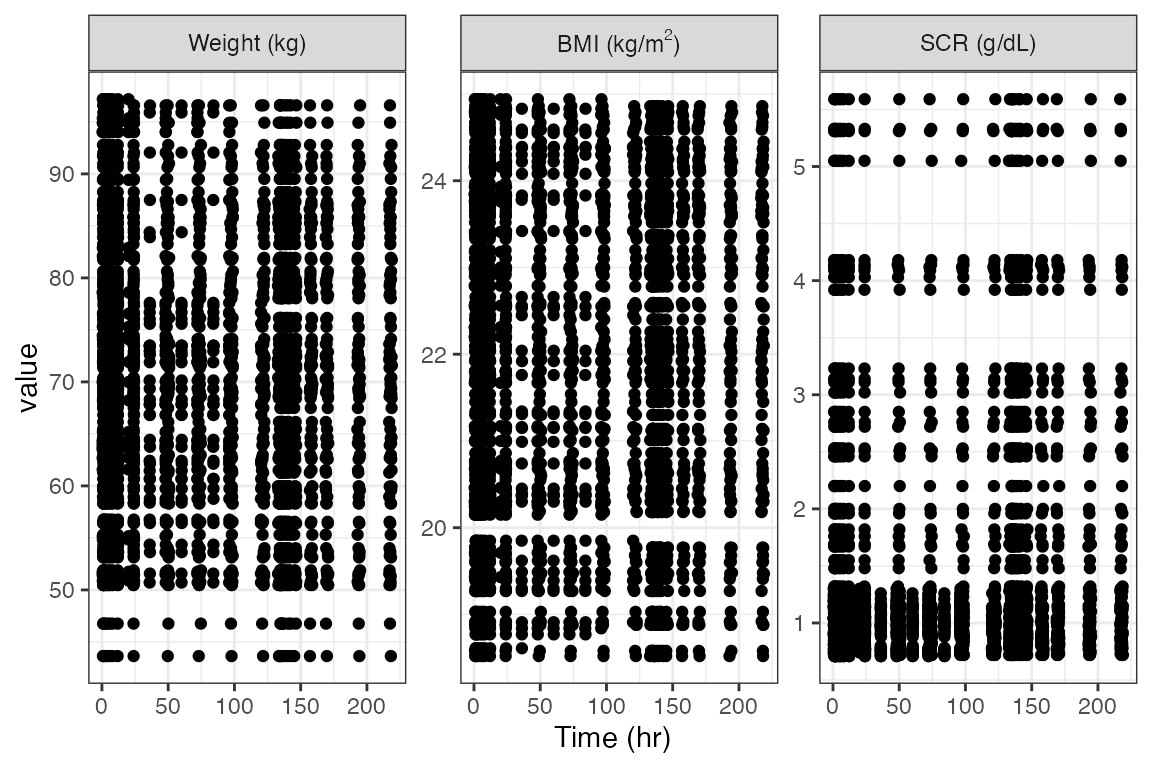
Add layers
p <- ggplot(df, aes(PRED,DV)) + geom_point() + pm_theme()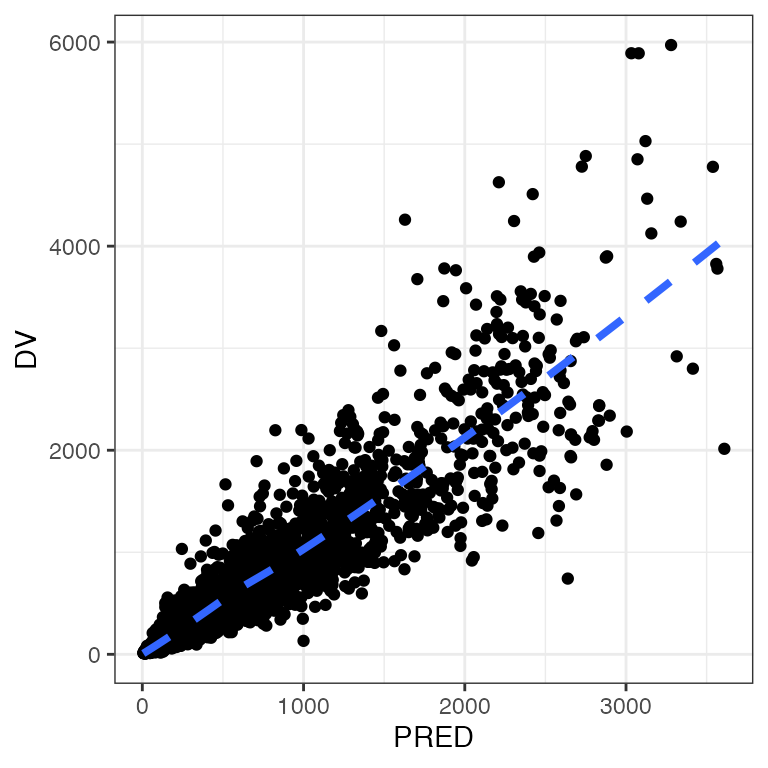
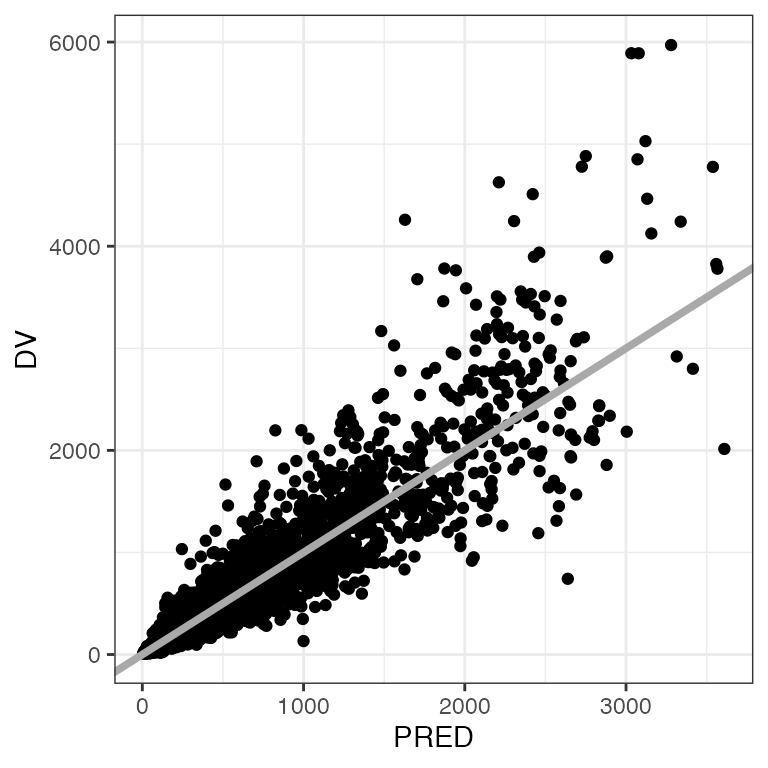
Drop extra layers
dv_pred(df, smooth=NULL)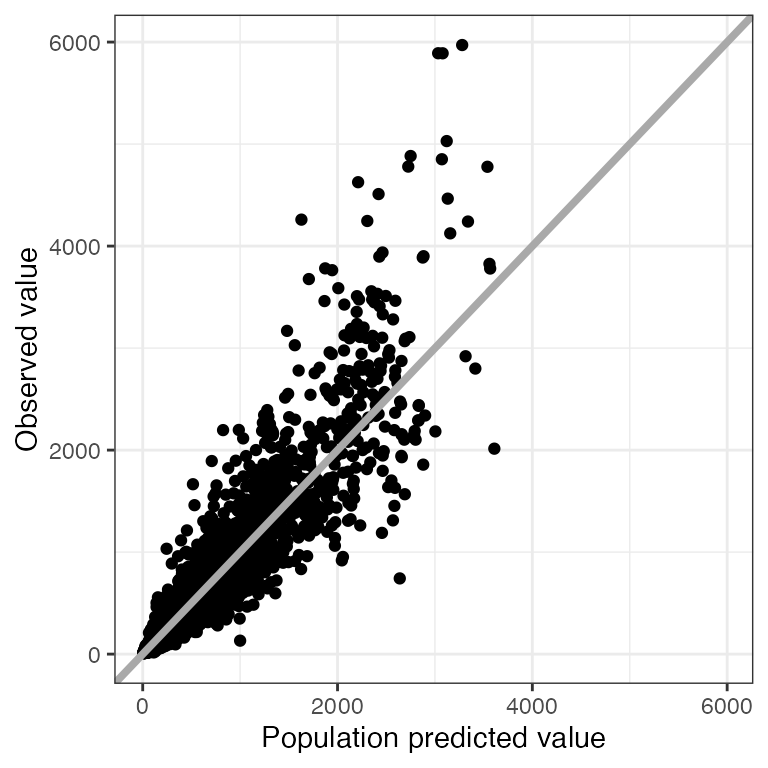
dv_pred(df, abline=NULL)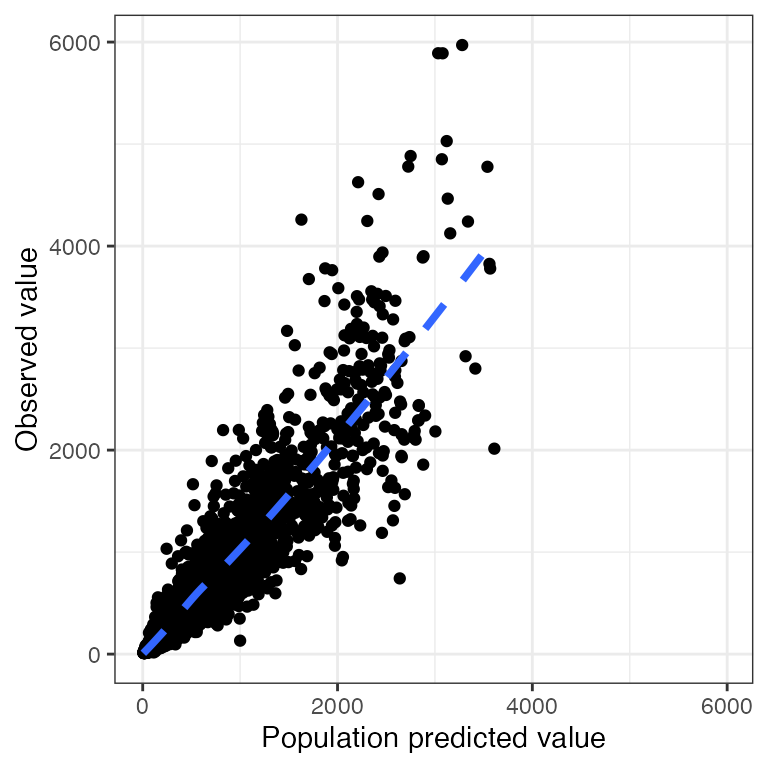
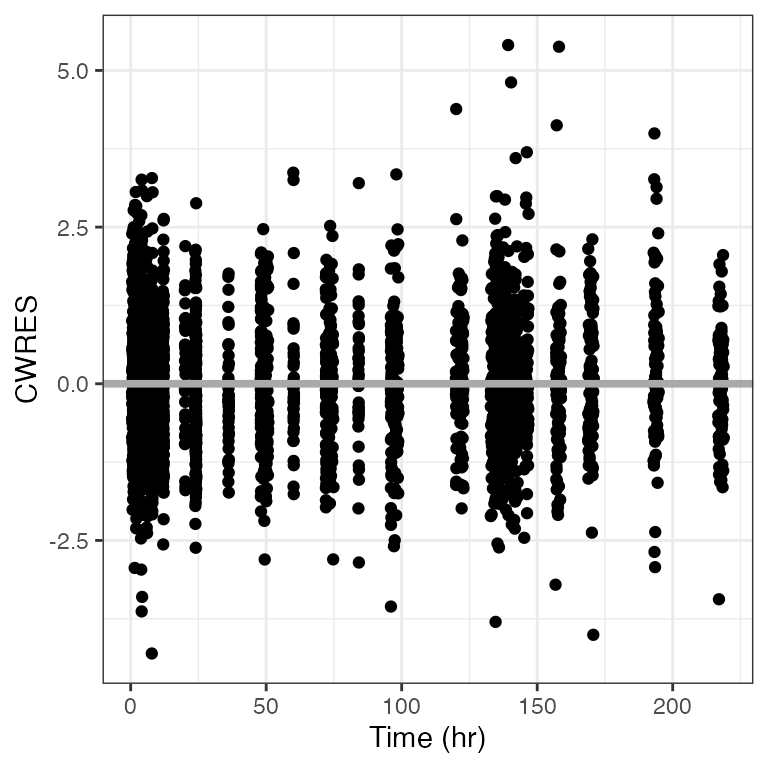
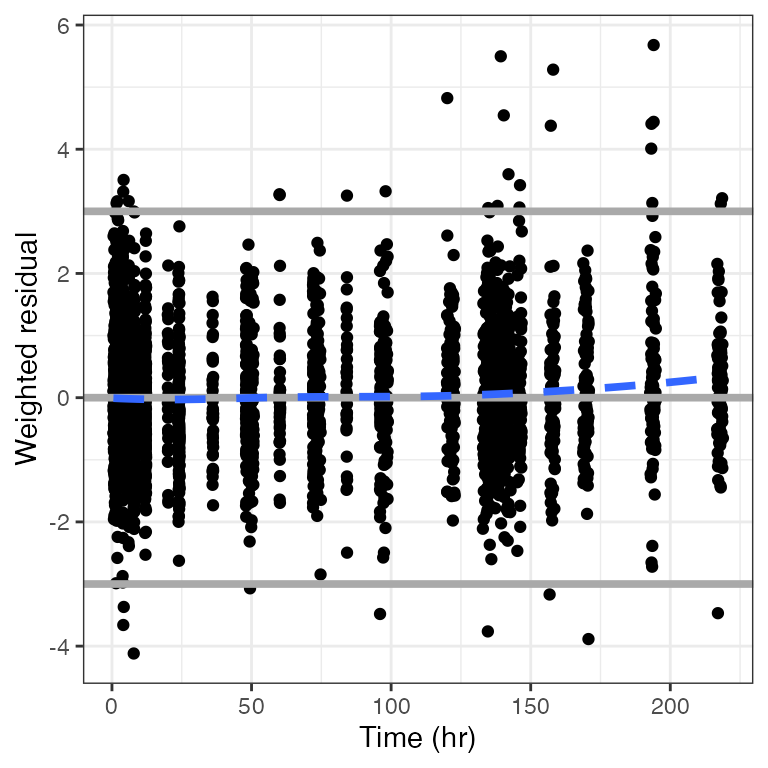
cwres_time(df, hline = NULL)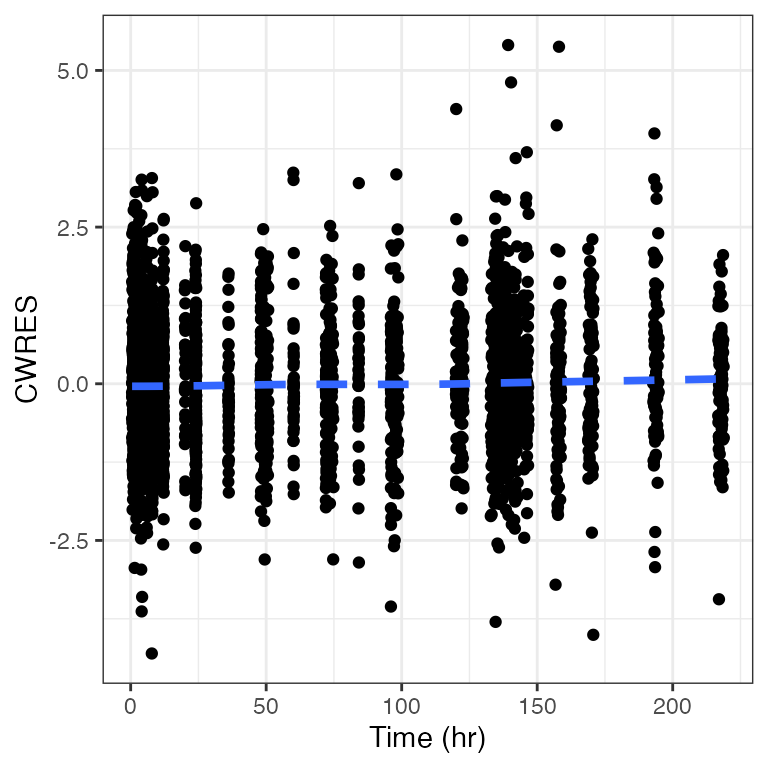
dv_pred(df, abline=NULL, smooth = NULL)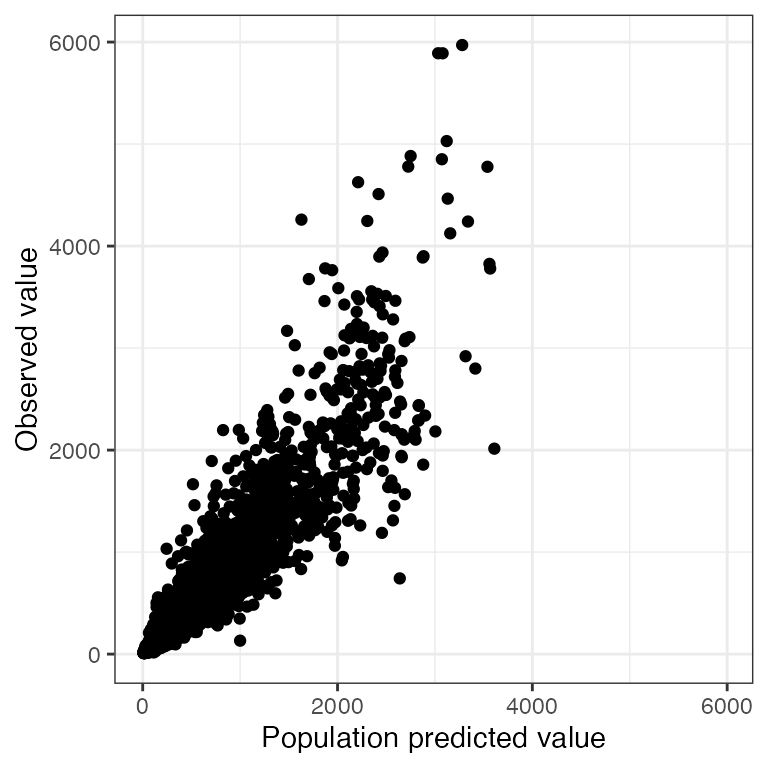
Modify layer specs
For example, change the values of argument for
geom_smooth
cwres_time(df, smooth = list(method = "loess", span = 0.1, se=TRUE))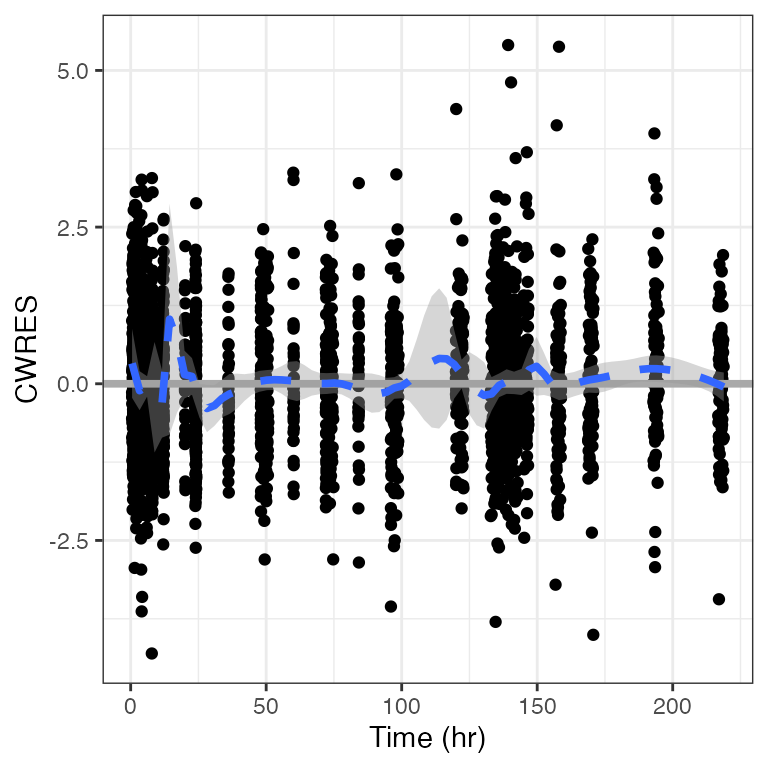
Custom breaks
Default breaks:
dv_time(df)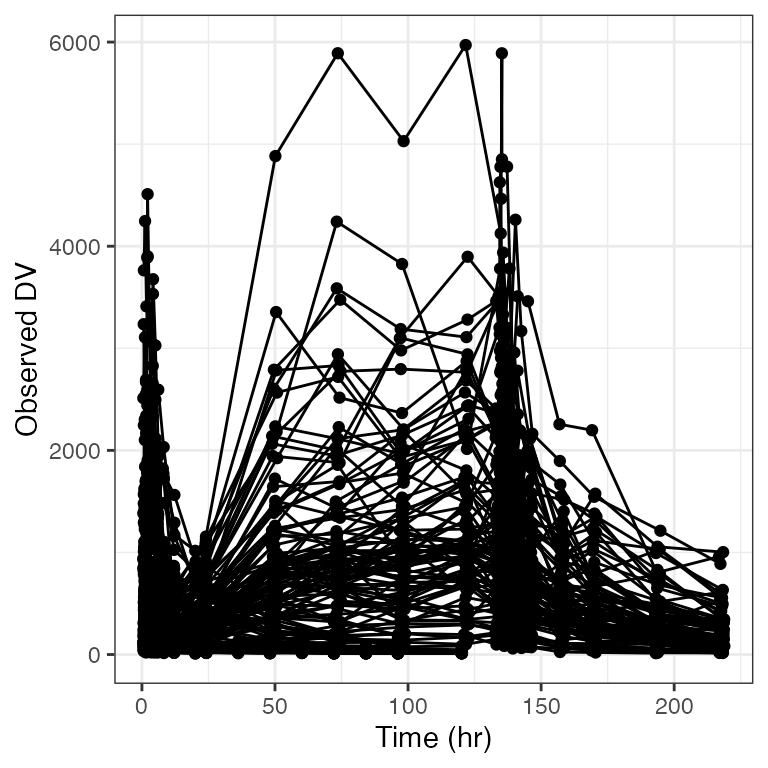
Break every 3 days
dv_time(df, xby=72)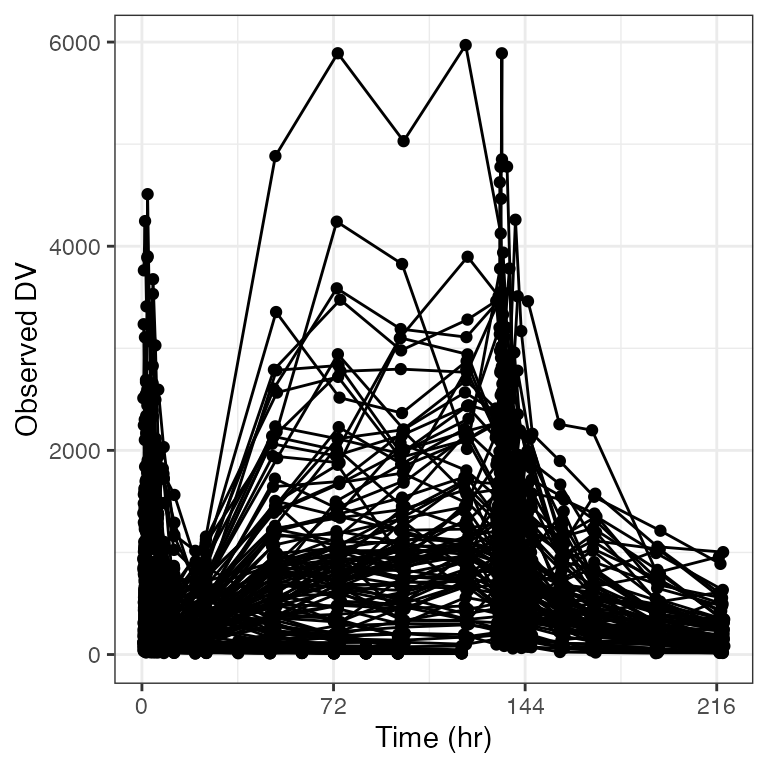
Custom breaks and limits
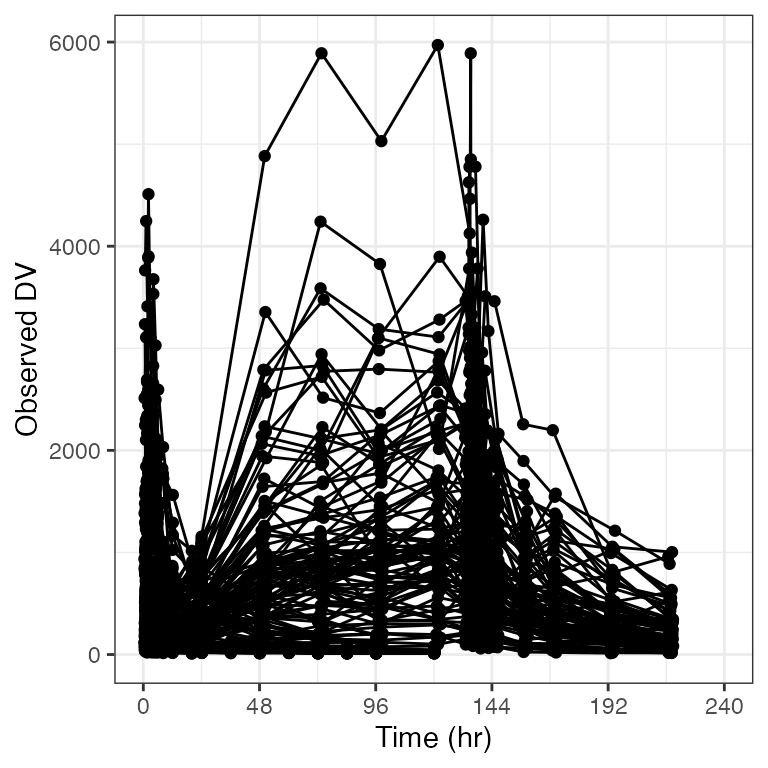
Replicate look and feel
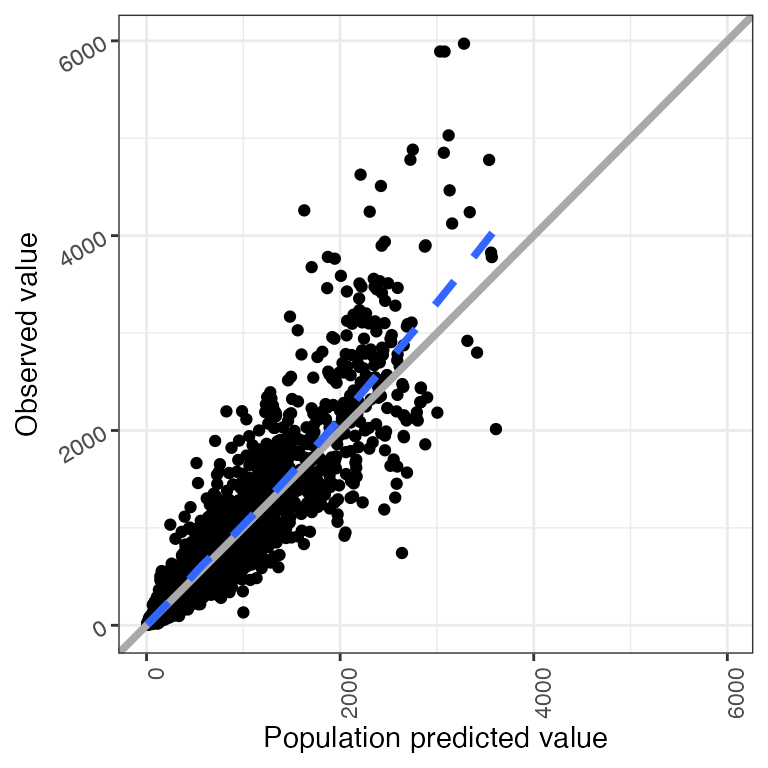
p <- ggplot(df, aes(IPRED,DV)) + geom_point()
p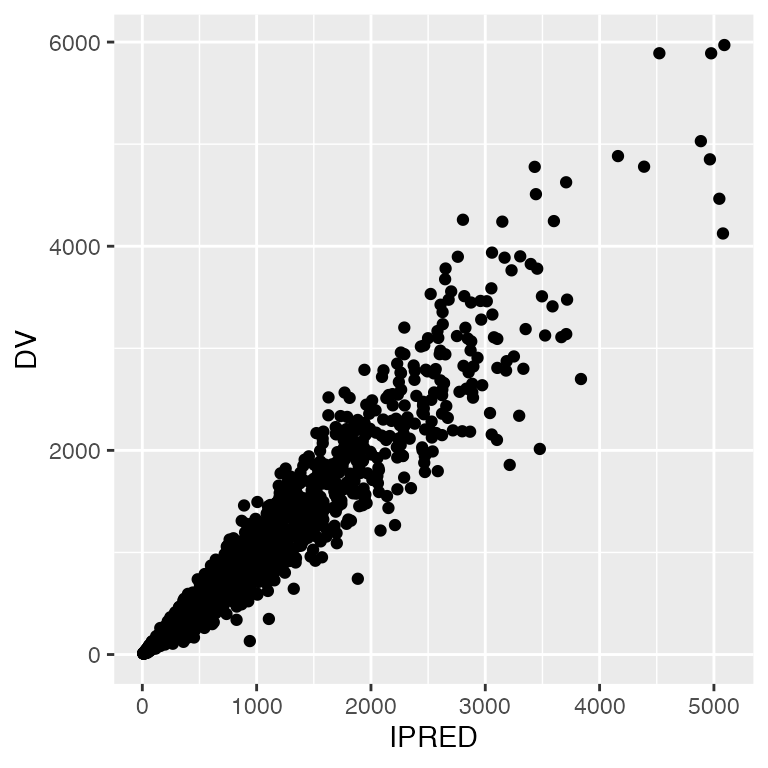
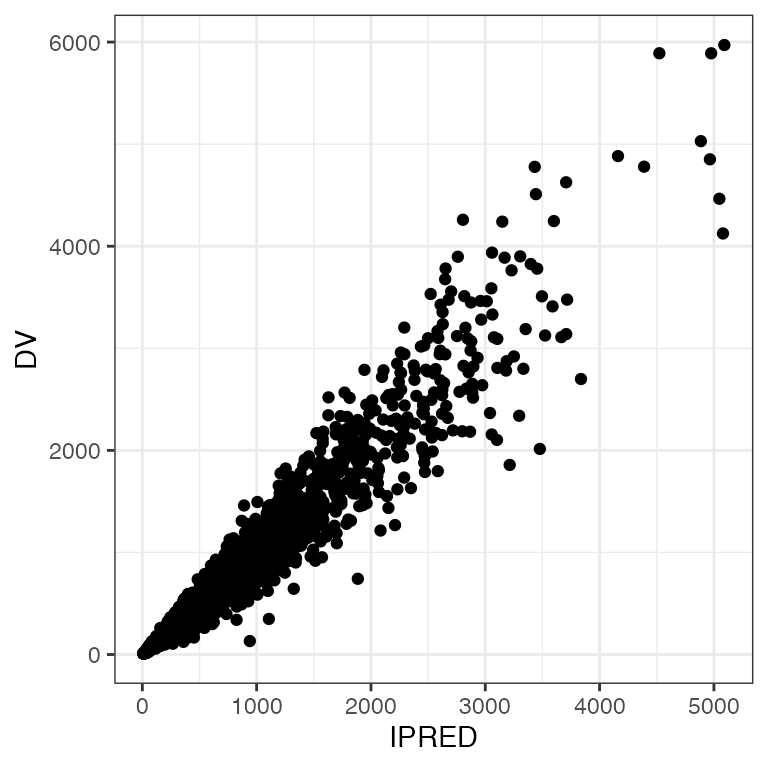
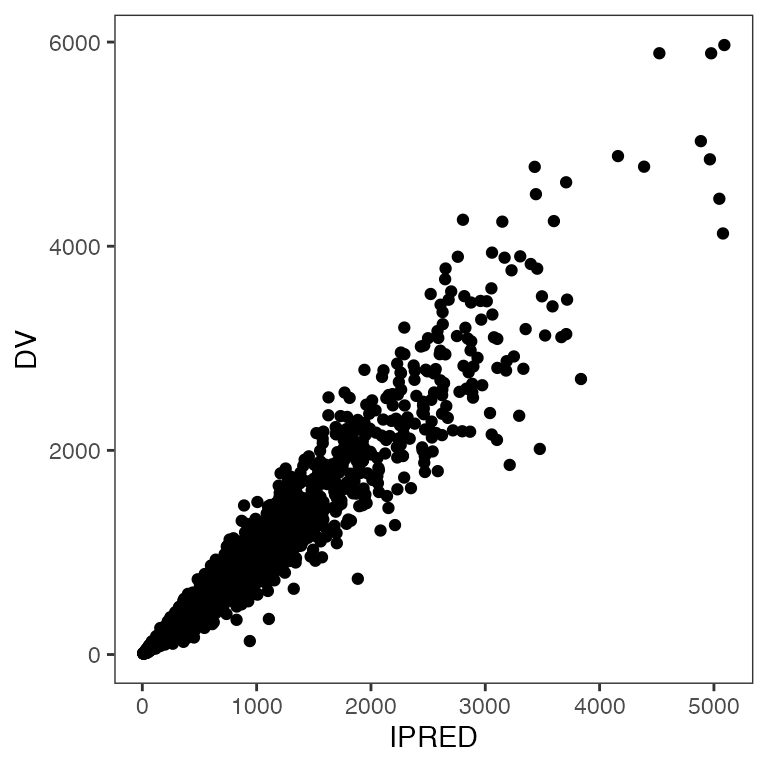
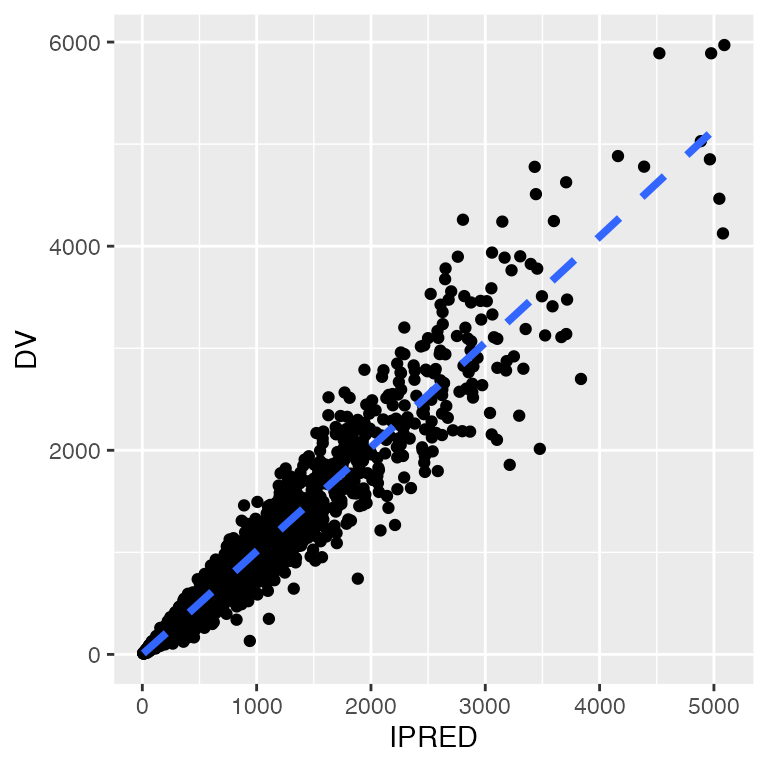
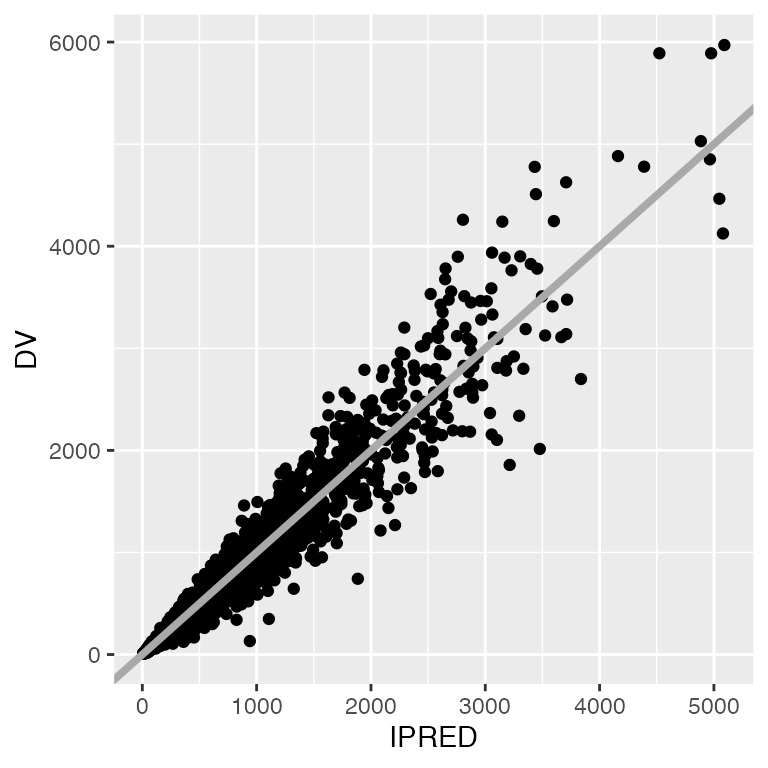
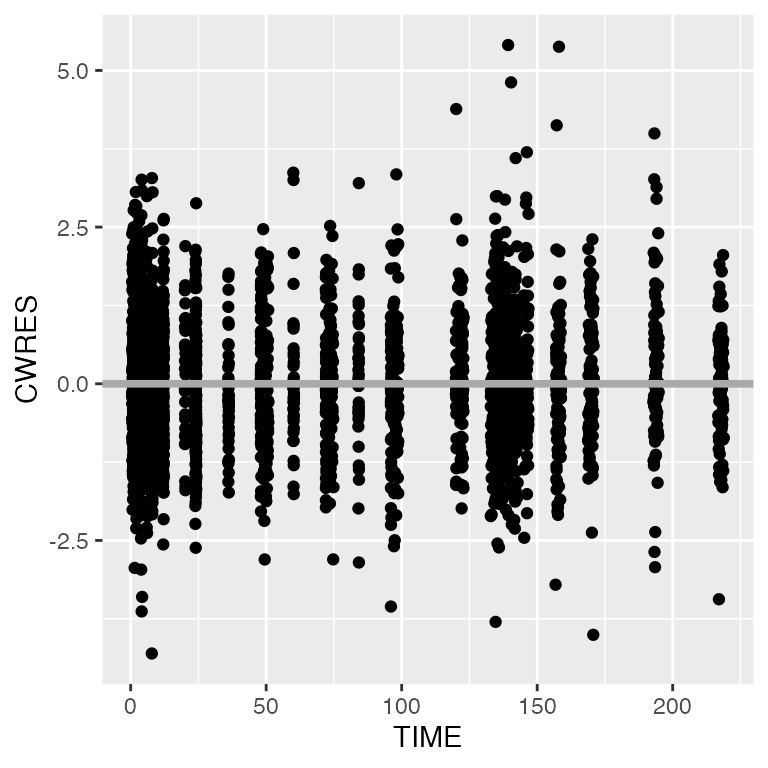
Rotate x and y axis labels
Rotate to vertical
We are typically rotating the tick labels on the x-axis and frequently it is convenient to ask for a totally vertical rendering
cwres_cat(df, x = "STUDYc") +
facet_wrap(~CPc) + rot_x(vertical = TRUE)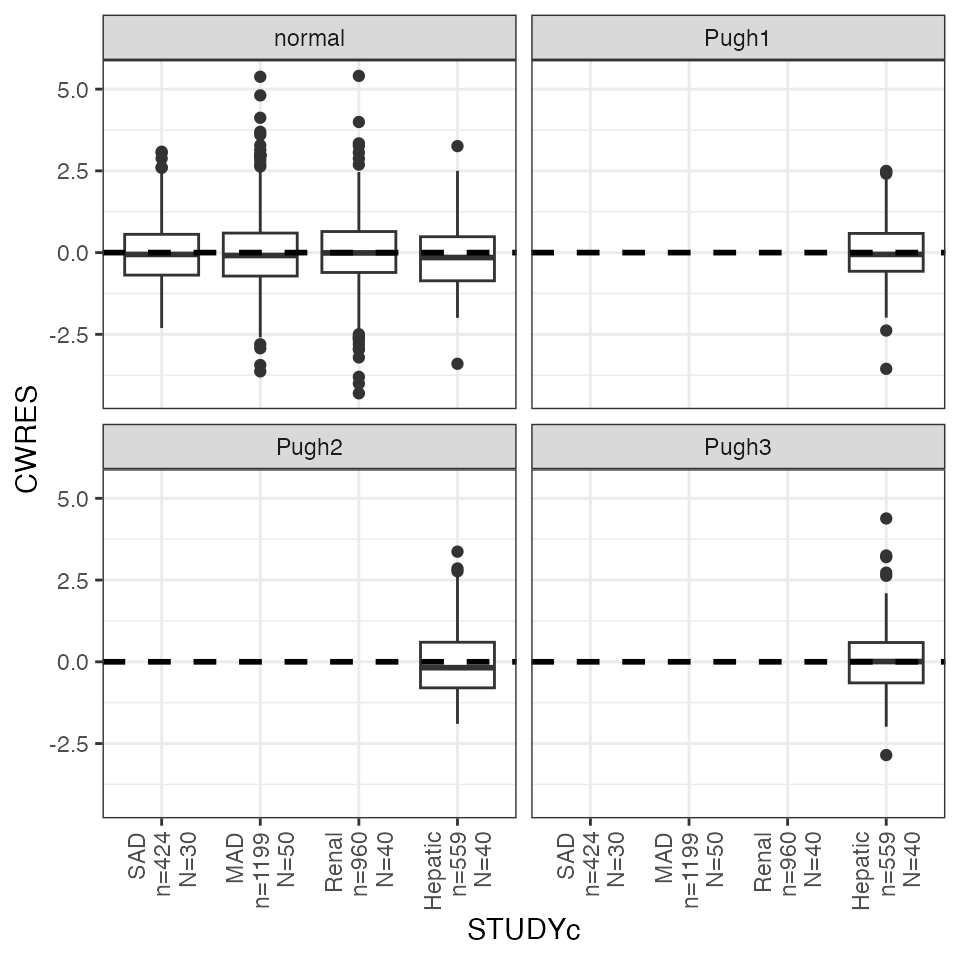
Standard axis titles
. [1] "TIME//Time {xunit}". [1] "TAD//Time after dose {xunit}". [1] "TAFD//Time after first dose {xunit}". [1] "RES//Residual". [1] "WRES//Weighted residual". [1] "CWRES//CWRES". [1] "CWRESI//CWRES with interaction". [1] "NPDE//NPDE". [1] "DV//Observed {yname}". [1] "PRED//Population predicted {xname}". [1] "IPRED//Individual predicted {xname}"Log breaks
logbr3(). [1] 1e-10 3e-10 1e-09 3e-09 1e-08 3e-08 1e-07 3e-07 1e-06 3e-06 1e-05 3e-05
. [13] 1e-04 3e-04 1e-03 3e-03 1e-02 3e-02 1e-01 3e-01 1e+00 3e+00 1e+01 3e+01
. [25] 1e+02 3e+02 1e+03 3e+03 1e+04 3e+04 1e+05 3e+05 1e+06 3e+06 1e+07 3e+07
. [37] 1e+08 3e+08 1e+09 3e+09 1e+10 3e+10
logbr(). [1] 1e-10 1e-09 1e-08 1e-07 1e-06 1e-05 1e-04 1e-03 1e-02 1e-01 1e+00 1e+01
. [13] 1e+02 1e+03 1e+04 1e+05 1e+06 1e+07 1e+08 1e+09 1e+10